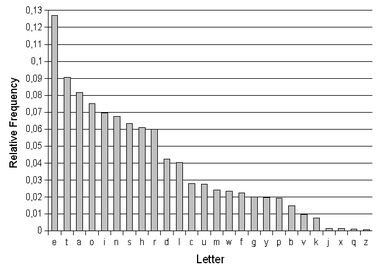
The frequency of the letters of the alphabet in English
The inventor of Morse code, Samuel Morse (1791-1872), needed to know this so that he could give the simplest codes to the most frequently used letters. He did it simply by counting the number of letters in sets of printers' type. The figures he came up with were:| 12,000 | E | 2,500 | F |
| 9,000 | T | 2,000 | W, Y |
| 8,000 | A, I, N, O, S | 1,700 | G, P |
| 6,400 | H | 1,600 | B |
| 6,200 | R | 1,200 | V |
| 4,400 | D | 800 | K |
| 4,000 | L | 500 | Q |
| 3,400 | U | 400 | J, X |
| 3,000 | C, M | 200 | Z |
| E | 11.1607% | 56.88 | M | 3.0129% | 15.36 |
| A | 8.4966% | 43.31 | H | 3.0034% | 15.31 |
| R | 7.5809% | 38.64 | G | 2.4705% | 12.59 |
| I | 7.5448% | 38.45 | B | 2.0720% | 10.56 |
| O | 7.1635% | 36.51 | F | 1.8121% | 9.24 |
| T | 6.9509% | 35.43 | Y | 1.7779% | 9.06 |
| N | 6.6544% | 33.92 | W | 1.2899% | 6.57 |
| S | 5.7351% | 29.23 | K | 1.1016% | 5.61 |
| L | 5.4893% | 27.98 | V | 1.0074% | 5.13 |
| C | 4.5388% | 23.13 | X | 0.2902% | 1.48 |
| U | 3.6308% | 18.51 | Z | 0.2722% | 1.39 |
| D | 3.3844% | 17.25 | J | 0.1965% | 1.00 |
| P | 3.1671% | 16.14 | Q | 0.1962% | (1) |
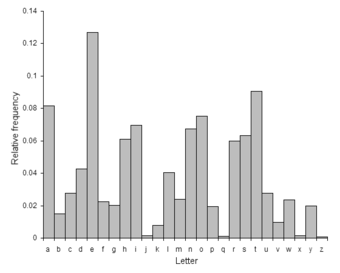
The third column represents proportions, taking the least common letter (q) as equal to 1. The letter E is over 56 times more common than Q in forming individual English words.
The frequency of letters at the beginnings of words is different again. There are more English words beginning with the letter 's' than with any other letter. (This is mainly because clusters such as 'sc', 'sh', 'sp', and 'st' act almost like independent letters.) The letter 'e' only comes about halfway down the order, and the letter 'x' unsurprisingly comes last.
A visual representation of relative frequencies is shown below: