Chapter 9, Table 1: Analysis of Covariance via SPSS
Syntax
The following data represent a pre-post design, where
a training program designed to assist people in losing weight is evaluated. An initial
measure of weight is collected to use as a baseline measure (specifically as a
covariate in the present analysis) and then participants are randomly assigned to
one of two groups. At the end of the training program another measure of weight
is obtained. The question of interest is: “did the participants who received
the treatment lose more weight than those that were assigned to the wait-list
control group?”
The analysis data given in Table 9.1 begins by making use of the SPSS Univariate ANOVA procedure (UNIANOVA). The difference in this design compared to those examined previously is that a covariate is included in the analysis. As before, we will begin by writing out the syntax for a univariate ANOVA. The major difference in the present situation is that a WITH statement is included on the second line of the syntax. The WITH statement proceeds the covariates of interest, in this case x (the initial weight). Also notice the /PRINT = PARAMETER line included in the syntax. Without this option the ANCOVA is performed and thus the F and probability values are given for each of the effects in the analysis. However, we are also interested in the parameter estimates, namely the slope and the intercept. Including the /PRINT = PARAMETER option provides the parameter estimates in addition to their tests of significance.
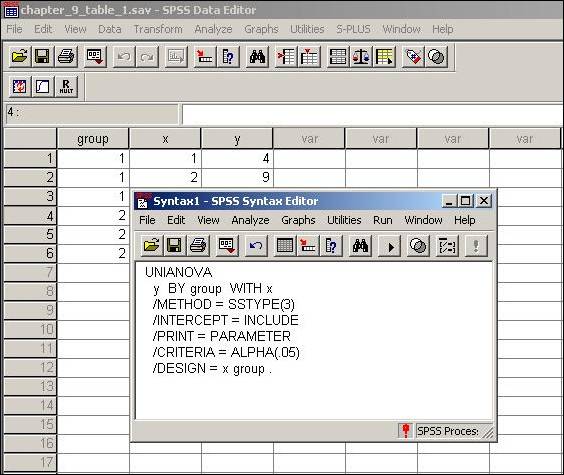
At this point clicking Run and then All will yield the ANCOVA results for the data given in Table 9.1.