
My research lies at the intersection of machine learning, network science and social media. Generally speaking, I am interested in uncovering how humans consume and curate information.
Click each description below to learn more about each project
Current Projects
- Advancing Media Literacy for New Digital Arrivals in Developing Countries
2018--2020
Source: USAID
Amount: $796,343 (Lead PI)
Project Description:The threat posed through online and social media vehicles is particularly compelling in that ordinary citizens will both consume and spread (mis)information through their online activity, affecting thousands of individuals instantly with falsehoods that are then implicitly endorsed by a seemingly qualified source. This issue is especially problematic for new digital arrivals who are least likely to understand the dynamics of these complex social and technical systems.
One of the primary consequences of the online and social media environment is that a handful of motivated, malicious individuals are capable of disrupting the information landscape. Tactics vary across regions due to social and design differences in popular online and social media systems. For example, the most popular online and social media platform in Nigeria is WhatsApp, which has very different social mechanics and design than, say, Facebook, which is the most popular social platform in Indonesia.
Due the relative ease of social media manipulation and their large impact on behavior and belief, it is widely expected that malicious individuals and groups will continue to spread harmful and false information. This is especially the case in the lead up to national democratic elections.
At a time when communities around the world increasingly turn to digital source for information, online and social media systems play a critical role in affecting attitudes and behavior. A core problem is that social media channels are being manipulated by malicious groups to spread misinformation in low and middle income countries (LMIC) to exacerbate social divides and influence citizen involvement in democratic processes. The spread and adoption of misinformation through digital channels is especially problematic because many users of online and social media systems are not aware of how (mis)information is spread through these channels. Notre Dame’s goal is to improve media literacy in low and middle income countries (LMIC) especially among new digital arrivals through a targeted digital media literacy campaign. Specifically, the team research question is: if Notre dame can provide customized online media literacy content to segmented audiences of new digital arrivals, then the recipients of media literacy will be less likely to engage with and spread misinformation.
- CAREER - Principled Structure Discovery for Network Analysis
2017--2022
Source: National Science Foundation
Amount: $592,565 (Single PI)
Project Description:The long term goals of the PI are to develop, study, and evaluate fundamentally new techniques for the discovery of interesting structural patterns and their function within real world networks while integrating educational and outreach programs that inspire future data mining practitioners and researchers. In support of these goals, this CAREER proposal will to develop and evaluate principled techniques that learn the Lego-like building blocks of real world networks. Then, these network patterns will be used to gain insights into the mechanisms that underlie network structure and evolution.
The ideas in this proposal originate from a newfound relationship between graph theory and formal language theory discovered by the PI and his collaborators. The relationship between graph theory and formal language theory allows for a Hyperedge Replacement Grammar (HRG) to be extracted from any graph without loss of information. Like a context free grammar, but for graphs, the extracted HRG contains the precise building blocks of the network as well as the instructions by which these building blocks ought to be pieced together. Because of the principled way it is constructed, the HRG can even be used to regenerate an isomorphic copy of the original graph. By marrying the fields of graph theory and formal language theory, lessons from the previous 50 years of study in formal language theory, grammars, and much of theoretical computer science can now be applied to graph mining and network science! This proposal takes the first steps towards reconciling these disparate fields by asking incisive questions about the extraction, inference, and analysis of network patterns in a mathematically elegant and principled way.
The discovery and analysis of network patterns is central to the scientific enterprise. Thus, extracting the useful and interesting building blocks of a network is critical to the advancement of many scientific fields. Indeed the most pivotal moments in the development of a scientific field are centered on discoveries about the structure of some phenomena. For example, chemists have found that many chemical interactions are the result of the underlying structural properties of interactions between elements. Biologists have agreed that tree structures are useful when organizing the evolutionary history of life, sociologists find that triadic closure underlies community development, and neuroscientists have found ``small world'' dynamics within neurons in the brain. In other instances, the structural organization of the entities may resemble a ring, a clique, a star, a constellation, or any number of complex configurations. Unfortunately, current graph mining research deals with small pre-defined patterns or frequently reoccurring patterns, even though interesting and useful information may be hidden in unknown and non-frequent patterns. Principled strategies for extracting these complex patterns are needed to discover the precise mechanisms that govern network structure and growth. This is exactly the focus of this project: to develop and evaluate techniques that learn the building blocks of real world networks that, in aggregate, succinctly describe the observed interactions expressed in the network.
The key insight for this task is that a network's clique tree (also known as the tree decomposition, junction tree, intersection tree, or cluster graph, depending on the context) encodes robust and precise information about the network. An HRG, which is extracted from the clique tree, contains graphical rewriting rules that can match and replace graph fragments similar to how a Context Free Grammar (CFG) rewrites characters in a string. These graph fragments represent a succinct, yet complete description of the building blocks of the network, and the rewriting rules of the HRG represent the instructions on how the graph is pieced together. Although the isomorphic guarantees are exciting and important, this proposal will focus instead on finding meaning in the building blocks and their instructions.
This proposal will substantially advance the state-of-the-art in graph mining in three specific ways: (1) The PI will create precise and principled algorithms for structure discovery, extraction, sampling, and robust evaluation for static and dynamic graphs, (2) The extracted structures will be used to infer the future growth and hidden structure of the network, and (3) The discovered patterns will be analyzed and mapped to real world mechanisms of network structure and growth. This proposal will also accelerate collaboration with chemical, social, and natural language scientists to produce practical applications of principled structure discovery on real world data.
- Mining Conversation Trails for Effective Group Behavior
2017--2020
Source: Army Research Office
Amount: $360,000 (Single PI)
Project Description:Group decisions are often made after lengthy, careful deliberation involving conversation, argument and a general back-and-forth among participating individuals who each possess their own distinct characteristics and biases. Critical decisions, especially, are made by a group where consensus drives the ultimate choice; yet we have all been party to groups where the ultimate decision, although the result of some consensus, was suboptimal. We therefore propose to study group-decision making processes in order to develop a suite of novel models and tools that can offer specific insights into the group decision-making process.
Our key contributions lie in the treatment of human conversation and discussion as trails over a concept graph. With this perspective, an individual's ideas (as expressed through language) can be mapped to explicit entities or concepts, and a single argument or train-of-thought can be treated as a trail/walk over the nodes in a concept graph. Therefore, within a group discussion we will first translate the stated positions, arguments, and stories into a set of distinct paths over a concept graph. Once in graph form, group dynamics can be analyzed as a new type of graph mining problem where agents synchronously traverse concepts, and where existing graph mining methods can be applied to answer many new, interesting questions about the nature of human discussion.
Unlike existing network models where nodes represent individuals and information flows over the edges between the individuals, our key idea is to flip this model such that network nodes represent concepts over which individuals walk during a group discussion. In this new mode of thinking important scientific questions will be addressed -- although we expect to raise more questions than we answer. For example: How do we map group discussion to a concept graph? Do conversation trails match human paths through existing knowledge graphs? What, if any, graph patterns exist in the conversation trails? How can we leverage outcomes from previous discussions to predict aspects of leadership, social cognition, and group decision making? The study of conversational trails for effective group behavior is a critical step towards a deeper understanding of the complex interactions between and among individuals.
Effective group discussion touches nearly every aspect of modern society, and although the command structure of the military is strictly hierarchical, many military decisions are arrived at after careful group discussion. We look at this old problem in a new way; by tackling fundamental scientific challenges we will not only open a fertile area of future scientific research, but directly impact how military leadership studies group decision making and other collective behavior.
- COSINE: Cognitive Online Simulation of Information Network Environments
2017--2021
Source: DARPA
Amount: $4,950,000 (with Indiana University and University of Southern California)
Amount to ND: $280,000
Project Description:The goal of this project is to create a cognitive agent simulation framework for studying social behavior in online information environments. We are developing a scalable, virtual laboratory, calibrated on real-world data, for studying dynamics of online social phenomena and information diffusion at different temporal resolutions and at multiple scales, from individual to community to global collective behavior.
Individual agent models within COSINE will be based on first-principles of human behavior uncovered through empirical analysis of the vast troves of online behavioral data. These models will incorporate bounded rationality and cognitive biases within models of attention. In addition, COSINE’s multi-resolution, scalable framework will enable time-resolved, massive simulations of dynamic information environments.
Key to COSINE’s success will be its ability to model complex phenomena arising in multiplex networked information environments. To achieve this, COSINE will incorporate networks into interactions between agents, thereby enabling the study of the interplay between individual behaviors and network structure, including (a) how individual traits affect where in the network individuals position themselves, (b) the information environment these positions produce, and (c) the impact this has on individual behavior. Finally, the system will be calibrated on real-word data collected from a plethora of online platforms.
- Deception Detection, Tracking and Factuality Assessment in Social and News Media
2017--2019
Source: Pacific Northwest National Laboratory - Department of Energy
Amount: $27,600 (Single PI)
Project Description:Deception Detection and Tracking LDRD Project with Pacific Northwest National Laboratory (PNNL) and University of Notre Dame will (Task 1) analyze evolution of deceptive news content on Reddit, and (Task 2) study deceptive video propagation and influence on YouTube. The focus tasks will involve running quantitative analysis and machine learning experiments to measure deception propagation and evolution in social networks. Such research will add to the foundation of social network analysis and machine learning used by academic, government and industrial agencies to measure information propagation and evolution in social media.
- High School and Undergraduate Research Apprenticeship Program
2018
Source: Army Research Office
Amount: $12,037 (Single PI)
Project Description:The key contribution of the prime project is in the treatment of human conversations and discussions as trails over a concept graph. With this perspective, an individual's ideas (as expressed through language) will be mapped to explicit entities or concepts, and a single argument or train-of-thought can be treated as a trail/walk over the nodes in a concept graph. Therefore, within a group discussion we will first translate the stated positions, arguments, and stories into a set of distinct paths over a concept graph. Once in graph form, group dynamics can be analyzed as a new type of graph mining problem where agents synchronously traverse concepts, and where existing graph mining methods can be applied to answer many new, interesting questions about the nature of human discussion.
Unlike existing network models where nodes represent individuals and information flows over the edges between the individuals, our key idea is to flip this model such that network nodes represent concepts over which individuals walk during a group discussion. A critical task in this project is to identify, collect and ``graphify'' group conversations found online and in the physical world.
Additionally, the PI is a performer on an NSF RET site (1609394) at the University of Notre Dame, which has hosted more than a dozen high school teachers during the summers of 2016 and 2017. During these RET-summers the PI has trained visiting high school science teachers in the principles of data science, machine learning, and text mining. Having received sufficient training in the previous summers, the goal for the summer of 2018 is to have the high school teachers engage in meaningful original research.
Here lies the opportunity for an interesting collaboration among all levels in the academic chain: we have the unique opportunity for the PI to work with well-trained high school science teachers alongside a computer science undergraduate and a high school student on a well defined, meaningful scientific research project. In addition to aiding in the scientific goals related to the primary project, this HSAP/URAP project will contribute lasting positive changes to the culture of the local high school.
Past Projects
- Socio-Digital Influence Attack Models and Deterrence
2014--2017
Source: Air Force Office of Scientific Research
Amount: $349,378 (Single PI)
Project Description:We rely on ratings contributed by others to make decisions about which hotels, books, movies, political candidates, news, comments, and stories are worth our time and money. The sheer volume of new information being produced and consumed only increases the reliance that individuals place on anonymous others to curate and sort massive amounts of information. Given the widespread use and economic value of socio-digital voting systems, it is important to consider whether they can successfully harness the wisdom of crowd to accurately aggregate individual information. There is a giant gap in our knowledge and capabilities in this area, including untested and contradictory social theories. Fortunately, these gaps can be filled using new experimental methodologies on large, socio-digital data sets. We will be able to determine if these socio-digital platforms produce useful, unbiased, aggregate outcomes, or (more likely) if, and how, opinion and behavior is influenced and manipulated. Work of our own and recent tangential experiments suggest that decisions and opinions can be significantly influenced by minor manipulations yielding different social behavior.
Based on these early indications, we will:
(1) Determine the manner by which social influence affects decision making and opinion formation in online social spaces; and
(2) Determine the causal relationship among influences, i.e., the extent to which aggregate opinion affects aggregate rating, and the extent to which ratings affect aggregate opinion.
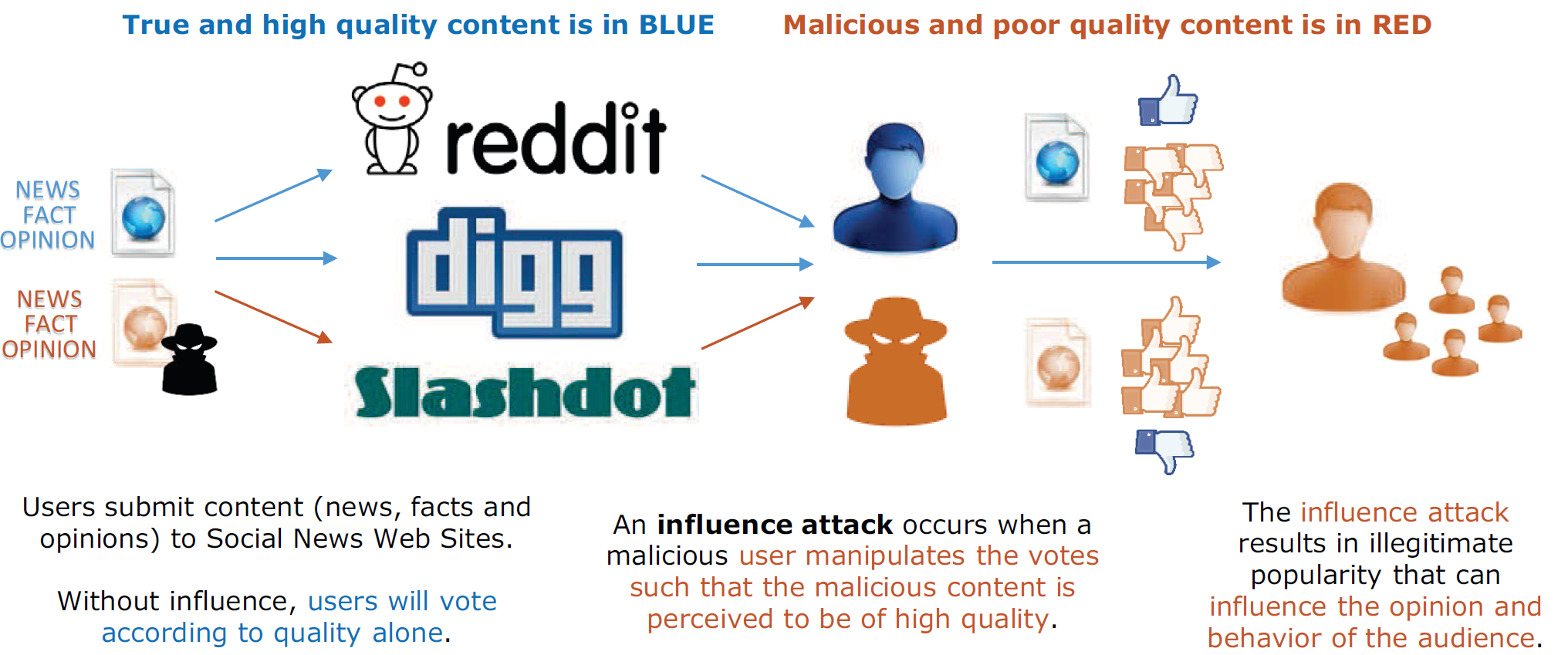
These determinations will be made via a set of experiments on various social news aggregation and commentary Web sites (hereafter referred to as social news sites) like Slashdot, Digg and Reddit. Based on statistical analysis of the experimental data we will be able to make conclusions regarding the manner by which social influence in online social spaces affects general decision making and opinion formation, and we will use these conclusions to:
(3) Formulate a general model of influence attacks in social media.
The results of these objectives are of critical interest to military intelligence and Military Information Support Operations (MISO, generally known as Psychological Operations (PsyOps)). Conflicts on the modern battlefield are successful not only with tanks and guns, but by winning hearts and minds. This is certainly not a secret; reports from recent conflicts have uncovered politically motivated computer hackers targeting American and Western digital assets. For example, the Syrian Electronic Army (SEA) – a collection of pro-government computer hackers aligned with Syrian President Bashar al-Assad – has successfully, although temporarily, crashed and/or defaced dozens of American Web sites.11 Foreign PsyOps groups are actively manipulating votes and ratings in social media platforms, and may therefore be actively manipulating Western public opinion. Based on these developments we will:
(4) Use the results and models developed from objectives 1–3 to develop deterrence strategies against foreign or malicious influence attacks may have on user behavior.
- Knowledge Hierarchies and Natural Navigation
2015--2016
Source: Templeton Foundation
Amount to ND: $58,000 (Subcontract via Univ. Chicago Prof. Evans)
Project Description:Open information extraction (OIE) extracts and learns relationships from free text; it is the data gathering process used to create the most widely-used knowledge networks. Extractable facts and relationships will vary greatly within the corpora, but in general we could expect to find support for declarations, assertions, theories and results, e.g., protein x interacts with protein y (describing protein protein interaction), or Facebook group x reacts to Facebook group y (describing information cascades), among countless other possibilities. The result these extractions will be a large set of "triples" describing the objects and the relationship, with links back to the source document, as well as the support (normalized count) of the fact, which is an indication of the triples' accuracy and/or veracity.
This data would then be made available to the Metaknowledge group and the scientific community at large. The extraction technology is rather straightforward, and there would be very little "research risk" involved, but admittedly the scientific novelty is also low. However, the significance and possible impact could be very large because no one has ever attempted OIE on a large scientific corpus before. The resulting dataset would be seed downstream novel and impactful downstream research and likely be used by many other members of the Metaknowledge network and the wider research community just as dbpedia, freebase and other knowledge networks have seeded many excellent downstream tasks.
Internally Supported Projects
- Knowledge and Social Network Analysis
2016--2017
Source: Notre Dame Rome Global Gateway
Amount: $35,500 (Single PI) - Constructing a Dataset of Catholic Parish Bulletins
2015--2016
Source: Notre Dame FRSP
Amount: $10,000 (Co-P.I. with ND Prof. Hungerman) - Verba Volant, Scripta Manent: Automatic Manuscript Analysis for the Vatican Secret Archives
2017--2018
Source: Notre Dame Research Office
Amount: $32,000 (co-PI with ND Prof. Chiang and ND Prof. Schreirer)