CHAPTER FOUR
Case #8: AUTOCORRELATION and SPURIOUS REGRESSION
Goal: This case examines the consequences of the common time-series problem of serial correlation (autocorrelation). Specifically, it introduces:
Problem Spreadsheet
The spreadsheet for this problem is CH4_Case2.xls. It contains the following data:
|
Variable |
Data Range |
|
CON |
1970Q1-1990Q4 |
|
GNP |
1970Q1-1990Q4 |
|
DIFF_CON |
1970Q1-1990Q4 |
|
DIFF_GNP |
1970Q1-1990Q4 |
The series CON is quarterly data on Personal Consumption Expenditure (seasonally adjusted in current dollars). This variable measures aggregate consumption expenditure.
The series GNP is quarterly data on Gross National Product (seasonally adjusted in current dollars). This variable measures the total value of goods produced in the national economy.
The series DIFF_CON is the first difference of CON calculated as.
DIFF_CONt = CONt — CONt-1
The series DIFF_GNP is the first difference of GNP calculated as above.
Keynesian Theory of Consumption
John Maynard Keynes, the father of modern macroeconomics, made two important theoretical observations about aggregate consumption behavior: (1) What was not consumed out of current income is saved; and (2) Current consumption depends on current income in a less than proportionate manner.
Keynes’ theories placed emphasis on a parameter called the marginal propensity to consume (MPC) which is the slope of the aggregate consumption function and a key factor in determining the "multiplier effect" of tax and spending policies.
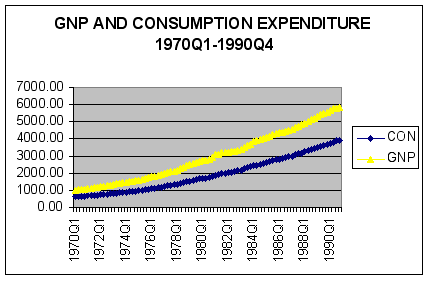
To examine behavior of personal consumption expenditure (CON) and gross national product (GNP) we generated a time-series plot in Excel.
Question #1: Based on examination of the time-series plot of CON and GNP, are these series stationary?
ANSWER:
To formally test whether both series are nonstationary, we estimated the autocorrelation function using the Analyze button in FORECASTXTM.
|
Obs |
CON ACF |
GNP ACF |
|
1 |
.9653 |
.9666 |
|
2 |
.9296 |
.9319 |
|
3 |
.8940 |
.8961 |
|
4 |
.8580 |
.8600 |
|
5 |
.8226 |
.8248 |
|
6 |
.7870 |
.7891 |
|
7 |
.7513 |
.7532 |
|
8 |
.7157 |
.7175 |
|
9 |
.6799 |
.6824 |
|
10 |
.6447 |
.6480 |
|
11 |
.6100 |
.6138 |
|
12 |
.5757 |
.5801 |
Correlograms for CON and GNP are reported below.
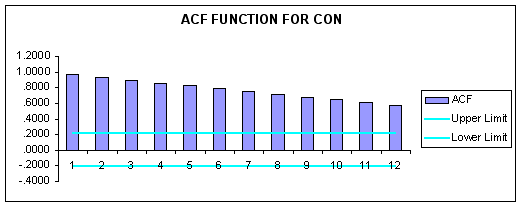

Question #2: Based on examination of the correlogram for each series, are the data stationary, i.e., can we reject all nulls of zero autocorrelation for a twelve-quarter lag structure at the 5-percent level of significance?
ANSWER:
Next, to examine the relationship between consumption and income, we estimated the correlation matrix for the two series using FORECASTXTM.
|
Audit Trail -- Correlation Coefficient Table |
||
|
Series |
||
|
Description |
CON |
GNP |
|
CON |
1.00E+00 |
9.99E-01 |
|
GNP |
9.99E-01 |
1.00E+00 |
Using Excel, a scatterplot of the data in levels is shown below.
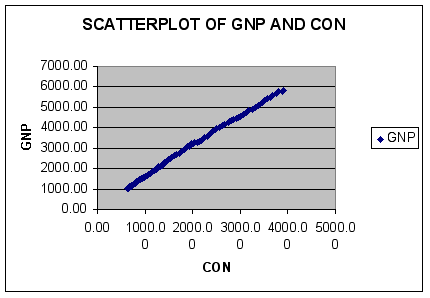
Question #3: Given the scatterplot and the estimated correlation between CON and GNP, do the two series appear to be related?
ANSWER:
Estimating the Marginal Propensity to Consume
Keynes’ analysis of the economy placed great emphasis on the size of the marginal propensity to consume (MPC), which determined the "multiplier effect" associated with fiscal and monetary policy. Keynes argued that the MPC was less than, but close to one.
We can obtain an estimate of the MPC by applying Ordinary Least Squares to the following aggregate consumption function:
GC =
a + bGNP + ewhere the slope parameter (b) is the marginal propensity to consume.
Estimation results of the Keynesian consumption function using FORECASTXTM are reported below.
|
Multiple Regression -- Result Formula |
||
|
CON = -99.00 + ( (GNP) * 0.673365 ) |
||
|
Audit Trail -- Coefficient Table (Multiple Regression Selected) |
|
|
|
|||
|
Series |
Included |
Standard |
Overall |
|||
|
Description |
in Model |
Coefficient |
Error |
T-test |
P-value |
F-test |
|
CON |
Dependent |
-9.90E+01 |
9.60E+00 |
-10.31 |
0.00 |
55,092.75 |
|
GNP |
Yes |
6.73E-01 |
2.87E-03 |
234.72 |
0.00 |
|
|
Accuracy Measures |
|
Value |
||
|
AIC |
852.80 |
|||
|
BIC |
855.23 |
|||
|
Mean Absolute Percentage Error (MAPE) |
2.12% |
|||
|
Sum Squared Error (SSE) |
123,189.23 |
|||
|
R-Square |
99.85% |
|||
|
Adjusted R-Square |
99.85% |
|||
Question #4: How well does this model fit the data? Explain!
ANSWER:
The forecaster should be suspicious however that these results may be overly optimistic. The reason is that both series are nonstationary and therefore may have a common trend. In other words, the regression may be plagued by serial correlation.
Testing for Serial Correlation
Using FORECASTXTM, we obtained the following estimate of the Durbin-Watson statistic.
|
Forecast Statistics |
Value |
|
|
Durbin Watson |
1.64E-01 |
|
Question #5: Does the data exhibit autocorrelation? Specifically, test the null hypothesis of no autocorrelation using the Durbin-Watson test.
ANSWER:
Correcting for Autocorrelation
When significant autocorrelation is present, spurious regression may arise in that our results appear to be highly accurate when in fact they are not, since the OLS estimator of the regression error variance is biased downward. To investigate this possibility, we will re-estimate our consumption function using first differences of the original data. This transformation is designed to eliminate any common linear trend in the data.
A scatterplot of the transformed series DIFF_CON and DIFF_GNP is shown below.
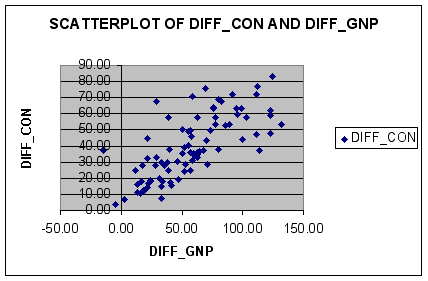
Note how the relationship between DIFF_CON and DIFF_GNP is still positive it is much more random than CON and GNP.
To test for stationarity in the first-differences of the data we produced the following correlograms using FORECASTXTM.
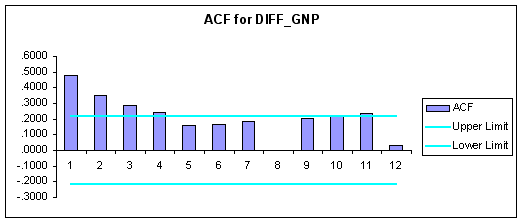
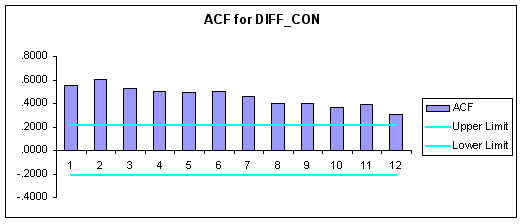
Question #6: Based upon the correlograms above are the first-differenced series stationary?
ANSWER:
Using FORECASTXTM, the following results were obtained from estimating the consumption function using DIFF_CON and DIFF_GNP.
|
Multiple Regression -- Result Formula |
||
|
DIFF_CON = 14.86 + ( (DIFF_GNP) * 0.42388 ) |
||
|
Audit Trail -- Coefficient Table (Multiple Regression Selected) |
|
|
|
|||
|
Series |
Included |
Standard |
Overall |
|||
|
Description |
in Model |
Coefficient |
Error |
T-test |
P-value |
F-test |
|
DIFF_CON |
Dependent |
1.49E+01 |
2.89E+00 |
5.14 |
0.00 |
93.84 |
|
DIFF_GNP |
Yes |
4.24E-01 |
4.38E-02 |
9.69 |
0.00 |
|
|
Accuracy Measures |
|
Value |
|
|
AIC |
672.97 |
||
|
BIC |
675.40 |
||
|
Mean Absolute Percentage Error (MAPE) |
38.04% |
||
|
Sum Squared Error (SSE) |
14,482.62 |
||
|
R-Square |
53.37% |
||
|
Adjusted R-Square |
52.80% |
||
Question #7: How well does the revised model fit the data? Explain!
ANSWER:
To examine whether serial correlation is still a problem we estimated the Durbin-Watson statistic for the revised model.
|
Forecast Statistics |
Value |
|
|
Durbin Watson |
1.76E+00 |
|
Question #8: By reference to the Durbin-Watson statistic, does the revised model exhibit autocorrelation? Specifically, test the null hypothesis of no autocorrelation using the Durbin-Watson test.
ANSWER: Given K = 1 and N = 84, Table 4-7 gives us:
dL = 1.62 and dU = 1.67.
Given d = 1.76, by application of Figure 4-12 leads us to conclude that we no longer have autocorrelation, i.e., we cannot reject the null in favor of positive autocorrelation.
Question #9: Compare the estimated coefficient of determination (R2), the estimated coefficient on the independent variable, the standard error of the estimated coefficient on the independent variable, and t-values for both versions of the model.
Does the original model in levels (CON and GNP) show signs of spurious regression? Explain.
ANSWER: Comparisons of the two models are summarized below:
|
Estimate |
Data in Levels |
Data in First Differences |
|
Slope Parameter (b) |
.6733 |
.4238 |
|
Std. Error of Slope Estimate |
.00287 |
.0438 |
|
t-statistic on Slope Estimate |
234.72 |
9.69 |
|
R-squared |
.9985 |
.5337 |
As we expect to find under autocorrelation, the two coefficient estimates are rather close, reflecting the fact that OLS slope estimator is still unbiased under autocorrelation, i.e., the slope estimates should converge for vary large samples.
On the other hand, the estimated standard error of the coefficient is much greater in the latter model than the former, consistent with OLS underestimating the regression variance in the first model. This is especially true for the t-statistics of the estimated slope coefficients, which differ by a factor of 200! Both of these results lead us to conclude that "Spurious Regression" plagues the first version of the model. In other words, the reported quality of our initial results is overstated.
Student Practice Questions
Question #1: Explain why researchers should always check their regression models for the presence of serial correlation. What is "spurious" about this problem?
Question #2: Repeat the analysis of this case using second differences of CON and GNP. Contrast and compare your results to those of this case.