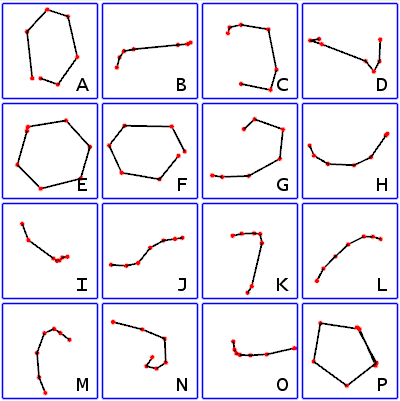
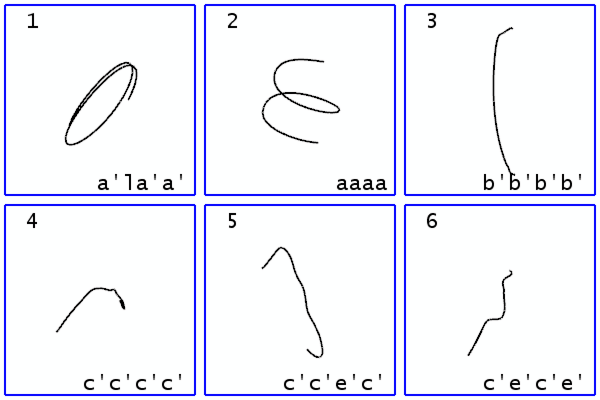
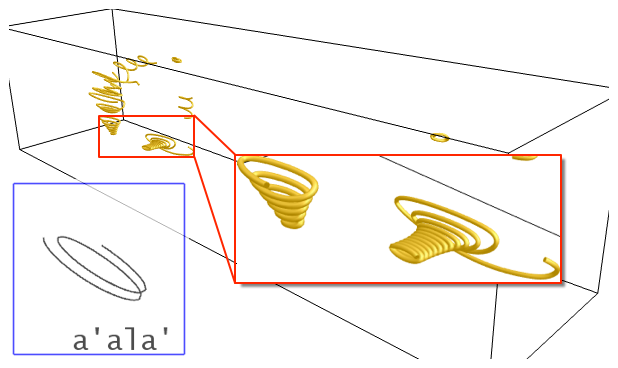
FlowString is an approach that extracts shape invariant features from streamlines and encodes each streamline into a string of well-selected characters. The set of all characters is called the alphabet. An alphabet can be extracted from a single data set or multiple data sets. We call the alphabet generated from multiple data sets the universal alphabet, which is shown below. Given the encoding of a set of streamlines, the most common patterns are achieved by the most frequently appeared substrings. Each of the most common patterns is called a word, and the set of all words is called the vocabulary. An image of the six words with the highest frequencies in the vocabulary of the solar plume data set is shown below. The streamline segments in a certain pattern can be queried by a string corresponding to that pattern. An image of the streamline segments matched by the string "a'ala'" is shown below.
 |
 |
 |
Jun Tao, Chaoli Wang, Ching-Kuang Shene, and Raymond A. Shaw. A Vocabulary Approach to Partial Streamline Matching and Exploratory Flow Visualization. IEEE Transactions on Visualization and Computer Graphics, 22(5):1503-1516, May 2016. [PDF] [WMV]
Jun Tao, Chaoli Wang, and Ching-Kuang Shene. FlowString: Partial Streamline Matching Using Shape Invariant Similarity Measure for Exploratory Flow Visualization. Proceedings of IEEE Pacific Visualization Symposium, Yokohama, Japan, pages 9-16, Mar 2014. [PDF] [WMV]