

| Since the dawn of time man has continued
to develop methods and machines to help solve complex physical problems.
From the first abacus to the most recent generation of computers, these
tools and the people who created them have inspired other researchers
to explore possibilities beyond the limits of conventional technology,
where intricate computer simulations and detailed modeling are the norm
and millions of mathematical equations can be solved in a matter of seconds. In today’s world it is hard to imagine not using computers to analyze phenomena that are too small or too complex to experimentally study. But as few as 50 years ago engineers and scientists could not quickly or accurately model nonlinear systems, where the whole was not equal to the sum of the parts nor the effects directly proportional to the causes. The reason was simple enough. Researchers, who are bound to follow the rules of the physical world, were thinking in a linear fashion. They broke the problem up into parts, but when the sum of the parts didn’t equal the whole, the process was slow, painstaking, and often paralyzing.  Much of the progress during the 20th century was made because of man’s
ability to harness the computer for the processing, storing, and distribution
of information. The modern computer age began in the 1940s with the completion
of the Atanasoff-Berry Computer in 1942 and the Electronic Numerical
Integrator Analyzer and Computer (ENIAC) in 1945, two of the world’s
first electronic digital computers. Housed at the University of Pennsylvania’s
Moore School of Electrical Engineering, ENIAC’s function was to
have been the development of firing tables for World War II artillery,
so that gunners could quickly determine which settings to use for a particular
weapon given an identified target. Solutions to the governing equations
took the Ballistics Research Laboratory, normally responsible for providing
the data, days to solve. ENIAC was going to shorten that time dramatically.
The machine was commissioned in 1943, but by the time it was completed,
the war had been over for three months. Much of the progress during the 20th century was made because of man’s
ability to harness the computer for the processing, storing, and distribution
of information. The modern computer age began in the 1940s with the completion
of the Atanasoff-Berry Computer in 1942 and the Electronic Numerical
Integrator Analyzer and Computer (ENIAC) in 1945, two of the world’s
first electronic digital computers. Housed at the University of Pennsylvania’s
Moore School of Electrical Engineering, ENIAC’s function was to
have been the development of firing tables for World War II artillery,
so that gunners could quickly determine which settings to use for a particular
weapon given an identified target. Solutions to the governing equations
took the Ballistics Research Laboratory, normally responsible for providing
the data, days to solve. ENIAC was going to shorten that time dramatically.
The machine was commissioned in 1943, but by the time it was completed,
the war had been over for three months.Although ENIAC didn’t help the gunners, it did prove to be almost a thousand times faster than its predecessors. It could solve more than 5,000 equations per second. And, in spite of its drawbacks -- such as requiring two days and massive rewiring to reprogram the machine because of its punch cards and plug boards -- ENIAC was a shining example of what could be accomplished. ENIAC was the first step. The second came in 1953 at Los Alamos National Laboratory in New Mexico, when Enrico Fermi, John Pasta, and Stanislaw Ulam introduced the concept of a “computer experiment” and changed the course and function of computers in research forever. Computational science, as it’s known today, uses high performance or “super” computers and advanced software algorithms to solve real physical problems that defy pencil-and-paper calculations, the processing power of many computers, and traditional algorithms. When Fermi and his associates proposed this new avenue for research, they literally opened a whole new world. Problems previously “unsolvable” became less daunting as researchers, such as Fermi, John Von Neumann, and Edward Lorenz, began to combine computational science with theoretical and experimental science. For example, in the last 50 years researchers employing techniques, such as computational fluid dynamics or finite-element methods and molecular dynamic methods, have gained sufficient knowledge of nonlinear systems to enable remarkably precise characterization of those systems -- from the flow over a wing to the strength of a DNA molecule. Researchers in the College of Engineering at the University of Notre Dame are also employing high-end computational techniques to address a variety of problems. “High-performance computing,” says Joseph M. Powers, associate professor of aerospace and mechanical engineering, “is a tool that gives researchers the ability to reliably solve multiscale problems. That knowledge can then be applied to a wide range of applications.” “When you’re trying to solve a problem computationally, you use a variety, and sometimes a combination, of tools,” says Samuel Paolucci, professor of aerospace and mechanical engineering. It may be as simple as processing a standard model and method on one very powerful computer or a large cluster of computers able to handle the number and intensity of calculations required to solve the problem. The University offers two supercomputing centers: the Bunch-o-Boxes (B.O.B.) Laboratory and the High-performance Computing Cluster (HPCC). Located in Stepan Chemistry Hall, B.O.B. is one of the 500 fastest computers in the world. It was designed and built by the colleges of engineering and science to enhance high-end computing capabilities at Notre Dame. Researchers from throughout the University use B.O.B.  Edward J. Maginn, associate professor of chemical and biomolecular engineering,
estimates that approximately 90 percent of his research in molecular
dynamics is carried out within the B.O.B. cluster. Maginn and his students
focus on statistical mechanics and the structure-property relationships
of molecules in order to better understand the nature of specific materials
and how molecules within a material interact with one another. Edward J. Maginn, associate professor of chemical and biomolecular engineering,
estimates that approximately 90 percent of his research in molecular
dynamics is carried out within the B.O.B. cluster. Maginn and his students
focus on statistical mechanics and the structure-property relationships
of molecules in order to better understand the nature of specific materials
and how molecules within a material interact with one another.Cluster computing is perhaps better known as parallel computing. Mark A. Stadtherr, professor of chemical and biomolecular engineering and chair of the University’s technical computing committee, uses parallel computing strategies in the B.O.B. cluster and the University’s HPCC to solve global optimization problems and model the phase behavior of complex molecules. “We can solve complex problems faster and more reliably using high-performance computing,” says Stadtherr. “But it’s not simply a matter of taking the computation and moving it from a single processor to a parallel cluster. You have to think about how you’re going to take advantage of the parallel computing environment.” One method Stadtherr and colleagues have used is the Message Passing Interface (MPI), where individual processors communicate with each other by passing messages back and forth. “What this has allowed us to do,” he says, “is solve problems that we could not even imagine solving years ago.”  For some problems using traditional hardware alone -- whether one or
several computers -- is not sufficient. This is why many researchers
write their own very efficient software. For example, Joannes
J. Westerink, associate professor of civil engineering and geological sciences, and
students in the Computational Hydraulics Laboratory design, test, and
implement new algorithms and MPI based parallel processing code in order
to solve flow patterns and transport in the coastal ocean. The models
they produce provide a detailed array of information -- from the flood
heights of storm surges for the design of levees to intricate maps of
salt water intrusion into estuaries. Organizations using these computational
models include the United States Army and Navy, the National Ocean Service,
and the states of Texas and Louisiana, as well as universities and consultants
worldwide. For some problems using traditional hardware alone -- whether one or
several computers -- is not sufficient. This is why many researchers
write their own very efficient software. For example, Joannes
J. Westerink, associate professor of civil engineering and geological sciences, and
students in the Computational Hydraulics Laboratory design, test, and
implement new algorithms and MPI based parallel processing code in order
to solve flow patterns and transport in the coastal ocean. The models
they produce provide a detailed array of information -- from the flood
heights of storm surges for the design of levees to intricate maps of
salt water intrusion into estuaries. Organizations using these computational
models include the United States Army and Navy, the National Ocean Service,
and the states of Texas and Louisiana, as well as universities and consultants
worldwide.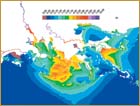 According to Westerink, many computer models and algorithms that worked
well 10 years ago don’t work today because the resolution has increased
so much. “It’s a constantly evolving process,” he says, “which
means that algorithms and software must be constantly improved. In order
to design accurate and efficient coastal hydrodynamic software, you must
consider the mathematical properties of algorithms, the architecture
of computers, the physics of the coastal ocean flows, and the ultimate
goal, which is to obtain a very useful design tool.” According to Westerink, many computer models and algorithms that worked
well 10 years ago don’t work today because the resolution has increased
so much. “It’s a constantly evolving process,” he says, “which
means that algorithms and software must be constantly improved. In order
to design accurate and efficient coastal hydrodynamic software, you must
consider the mathematical properties of algorithms, the architecture
of computers, the physics of the coastal ocean flows, and the ultimate
goal, which is to obtain a very useful design tool.”Another researcher using a very specific and efficient software program is Jesus A. Izaguirre, assistant professor of computer science and engineering. “The computer software we use as we study biological processes [CompuCell: Software for Morphogenesis] allows us to simulate the individual mechanisms of cells as they grow as well as their elaborate interactions.” The first step, according to Izaguirre, is to analyze the problem and develop a parallel or high-performance algorithm. The next is to develop and implement the software. “It is more complicated to produce software that is reliable when it is executing concurrently. But because of the combination we use -- clever algorithms and fast parallel implementations, we have enabled some simulations that other researchers have not yet been able to duplicate.” Izaguirre and colleagues use departmental resources as well as the high-performance clusters in the University’s HPCC and the B.O.B. lab. But they also employ supercomputing centers throughout the country.  Preprocessing, applying high-performance algorithms before beginning
a computational cycle, is a method Notre Dame researchers use to efficiently
solve multiscale problems. For example, in conjunction with Los Alamos
National Laboratory, Powers and Paolucci have been focusing their efforts
on the combustion of gases -- such as hydrogen-oxygen mixtures -- and
energetic solids, such as those used in the space shuttle booster rockets
and high explosives. “The combustion of these materials,” says
Powers, “involves a large range of temporal and spatial scales,
making the solution of mathematical equations modeling these processes
computationally challenging. We’ve been developing and refining
techniques that help us to better understand the combustion process and
to resolve the actual chemistry and material motion occurring during
combustion with a great deal of detail, speed, and accuracy.” Preprocessing, applying high-performance algorithms before beginning
a computational cycle, is a method Notre Dame researchers use to efficiently
solve multiscale problems. For example, in conjunction with Los Alamos
National Laboratory, Powers and Paolucci have been focusing their efforts
on the combustion of gases -- such as hydrogen-oxygen mixtures -- and
energetic solids, such as those used in the space shuttle booster rockets
and high explosives. “The combustion of these materials,” says
Powers, “involves a large range of temporal and spatial scales,
making the solution of mathematical equations modeling these processes
computationally challenging. We’ve been developing and refining
techniques that help us to better understand the combustion process and
to resolve the actual chemistry and material motion occurring during
combustion with a great deal of detail, speed, and accuracy.”Key to their research are the wavelet and low-dimensional manifold methods. According to Paolucci, the wavelet method uses the computer as both a mathematical microscope, capturing the length scales of the combustion process below the micron level, and a macroscope, viewing the entire process on the scale of centimeters. The low-dimensional manifold method applies sophisticated multidimensional techniques to identify low-dimensional surfaces that capture the essence of how important chemical reactions occur in nature. Additionally, Paolucci and Powers are developing a suite of high-performance algorithms for problems in computational mechanics. In fact, Paolucci recently completed a project that models the fluid mechanics and heat transfer associated with the solidification of a liquid metal alloy used in the manufacture of pistons. Funded by Federal Mogul, his task was to develop better methods to more quickly manufacture a casting while maintaining proper strength characteristics. Powers has also employed an ultra-accurate discretization algorithm to model the flow behind the bow shock experienced by vehicles such as the space shuttle during the re-entry process. With this algorithm he has developed a technique to optimize the vehicle shape so as to minimize the drag during re-entry.  Hafiz M. Atassi, the Viola D. Hank Professor of Aerospace and Mechanical
Engineering, creates specific algorithms for parallel computing platforms.
He uses these algorithms to simulate the noise produced in aircraft engines
and marine propellers. Working with the Office of Naval Research and
the Ohio Aerospace Institute Consortium, Atassi, postdoctoral research
associates Basman Elhadidi and Romeo Susan-Resiga, and students in the
Hessert Laboratory for Aerospace Research develop models that solve approximately
one to five million equations in a matter of hours. Hafiz M. Atassi, the Viola D. Hank Professor of Aerospace and Mechanical
Engineering, creates specific algorithms for parallel computing platforms.
He uses these algorithms to simulate the noise produced in aircraft engines
and marine propellers. Working with the Office of Naval Research and
the Ohio Aerospace Institute Consortium, Atassi, postdoctoral research
associates Basman Elhadidi and Romeo Susan-Resiga, and students in the
Hessert Laboratory for Aerospace Research develop models that solve approximately
one to five million equations in a matter of hours.“Using mathematics to develop highly accurate algorithms, we can simulate noise generation and propagation from aircraft engines and marine propellers. We have also developed algorithms for what we call the ‘Inverse Problem,’ so we can identify the source of a noise by examining the level and signature of the sound,” explains Atassi. “When we pinpoint the source of the sound using this method, we then have a better understanding of what creates the noise (generation) and how the sound wave travels (propagation).” The government has placed a high priority on noise reduction, particularly the noise produced by jet engines. Federal regulations now require reductions totaling 20 decibels over the next 20 years. “With our algorithms -- which are designed to reduce computational time and memory requirements -- and by using parallel processing, we can identify and control the parameters affecting noise generation,” says Atassi. Although he does use some of the computer facilities on campus, Atassi has developed close relationships with Argonne National Laboratory, the National Aeronautics and Space Administration (NASA), and the Navy, which he uses for large computational models. “But,” he says, “if the algorithms are not precise, it doesn’t matter how much processing power or how many computers you apply to the problem, you will not get an accurate representation of the sound.” The final way to ensure the fastest and most reliable processing of computationally intensive problems is to build a better computer. Computer architects at Notre Dame are investigating three new architecture structures: morphable architectures for better energy use; Processing-in-Memory (PIM) architectures for faster access and processing of items stored in memory; and molecular architectures, the development of an architecture based on Quantum-dot Cellular Automata (QCA) where the “chips” are the size of strands of DNA and the “transistors” are molecules. The impetus for each of these initiatives stems from today’s electronic applications -- multimedia, network servers and appliances, real-time embedded systems, and other computationally demanding systems or services -- together with an increasing push from emerging technologies. On a daily basis engineers and computer scientists are realizing that the computers of the future need to be radically different from those conceived and built even a decade ago. Morph project researchers -- Peter M. Kogge, the Ted H. McCourtney Professor of Computer Science and Engineering; Jay B. Brockman, associate professor of computer science and engineering; Kanad Ghose, chair and associate professor of the Department of Computer Science at the State University of New York at Binghamton; and Nikzad B. Toomarian of the Center for Integrated Space Microsystems at NASA’s Jet Propulsion Laboratory -- are working to develop a computer architecture whose energy and performance characteristics will adapt to available energy profiles. Their innovative approaches include developing memory hierarchies and adaptive algorithms for placing data within the hierarchies and adapting run-time operations and data structures to be more energy aware.  PIM is another focus of College of Engineering faculty. Current technology
dictates that logic and memory exist on two separate silicon chips. PIM
says that instead of two chips, one for memory and one for logic, a single
chip can be used for both functions. Computer processing time would be
drastically reduced because there would be no need to go from the processor
to the memory (to access information) and back again. PIM would also
greatly reduce power levels needed to operate a computer. “It’s
radically different from the way we execute computing now,” says
Kogge, “and, that’s very exciting.” PIM is another focus of College of Engineering faculty. Current technology
dictates that logic and memory exist on two separate silicon chips. PIM
says that instead of two chips, one for memory and one for logic, a single
chip can be used for both functions. Computer processing time would be
drastically reduced because there would be no need to go from the processor
to the memory (to access information) and back again. PIM would also
greatly reduce power levels needed to operate a computer. “It’s
radically different from the way we execute computing now,” says
Kogge, “and, that’s very exciting.”Researchers in the Department of Computer Science and Engineering, led by Kogge -- who was part of the IBM team that built a prototype PIM chip in February 1993 -- are developing new computer architectures that utilize PIM for a variety of applications. For example, the PIM team, working with collaborators at several institutions and led by the California Institute of Technology, is creating a hybrid technology multithreaded (HTMT) machine. This new type of supercomputer, which would feature PIM memory, would be capable of executing a petaflop -- 1015 flowing point operations per second, which is about one million times faster than what a decent personal computer can accomplish today. In another PIM project computer science and engineering faculty in collaboration with Cray Inc., the company that built and installed the first supercomputer at Los Alamos National Laboratory in 1976, are developing the memory functions for computers 10 times faster than the HTMT machine. The goal of this project, a three-year $43 million effort funded by the Defense Advanced Research Projects Agency as part of its High Productivity Computing Systems Program, is to build the first “trans-petaflops systems-computers able to perform more than a million billion calculations per second” and have a product available by 2010 for the national security and industrial user communities. PIM and some of the other methods being studied by Notre Dame researchers revolve around the use of conventional silicon and a transistor paradigm. Another avenue they are exploring focuses on nanotechnology, specifically using QCA to create circuit architectures. QCA was developed at Notre Dame. It “computes” not on the basis of electron flow but on Coulombic interactions. So when a signal from a control cell changes the state of one electron, it affects the next electron, which repels its neighbor and so on down a row of cells. How an array of quantum-dots is assembled determines how it functions -- memory, processing, or a unique molecular combination of both. To date Notre Dame faculty have developed a new CAD system for QCAs, created a layout and timing model that matches QCA characteristics, and designed a simple microprocessor. “It turns out that QCA is the natural next step from PIM. If we can build molecules that can ‘compute,’ and that’s still a long way off,” says Kogge, “then we can reduce the size of computers by a factor of 100. The power requirements and processing time would also go down incredibly. You could even conceive of putting ‘computers’ in something like paint or fabric.” Whether located in laboratories, woven into clothing, or scattered throughout paint, it’s apparent that the computers of tomorrow will be as different from the computers used today as the space shuttle is from the Kitty Hawk flyer. Molecules may process and store information inside the “box,” providing split-second solutions to large, complicated multiscale problems. There may not even be a “box.” But it will still be engineers and computer scientists overseeing the process, developing the algorithms and software needed for the next generation of computers, and finding ways to solve some of the most crucial problems on the planet. For more information on high-performance computing at Notre Dame, visit: B.O.B. Laboratory http://bob.nd.edu/ Computational Hydraulics Laboratory http://www.nd.edu/~coast/ Computer Architecture Projects at Notre Dame http://www.nd.edu/~cse_proj Hessert Laboratory for Aerospace Research http://www.nd.edu/~ame/facilities/Hessert.html High-performance Computing Cluster http://www.nd.edu/~hpcc/ Information Technology at Notre Dame http://www.cse.nd.edu/it@nd Interdisciplinary Center for the Study of Biocomplexity http://www.nd.edu/~icsb/ |