Homework 08: System Calls (I/O, Files, Directories)
The goal of this homework assignment is to allow you to practice using system calls involving I/O, files, and directories in C by implementing partial clones of dd and find:
-
duplicate: The first utility is calledduplicateand uses system calls dealing with low-level I/O to implement the dd command, which allows users to copy data from one file to another:$ ./duplicate -h Usage: ./duplicate [options] Options: if=FILE Read from FILE instead of stdin of=FILE Write to FILE instead of stdout count=N Copy only N input blocks bs=BYTES Read and write up to BYTES bytes at a time seek=N Skip N obs-sized blocks at start of output skip=N Skip N ibs-sized blocks at start of input -
search: The second utility is calledsearchand uses system calls dealing with files and directories to implement find, which recursively searches a directory and prints the items it finds based on the specified user options.$ ./search -help Usage: ./search PATH [OPTIONS] Options: -help Display this help message -executable File is executable or directory is searchable to user -readable File readable to user -writable File is writable to user -type [f|d] File is of type f for regular file or d for directory -empty File or directory is empty -name PATTERN Base of file name matches shell PATTERN -path PATTERN Path of file matches shell PATTERN -perm MODE File's permission bits are exactly MODE (octal) -newer fILE File was modified more recently than FILE -uid N File's numeric user ID is N -gid N File's numeric group ID is N
For this assignment, record your source code and any responses to the
following activities in the homework08 folder of your assignments
GitLab repository and push your work by noon Saturday, April 14.
Activity 0: Preparation (0.5 Points)
Before starting this homework assignment, you should first perform a git
pull to retrieve any changes in your remote GitLab repository:
$ cd path/to/repository # Go to assignments repository $ git checkout master # Make sure we are in master branch $ git pull --rebase # Get any remote changes not present locally
Next, create a new branch for this assignment:
$ git checkout -b homework08 # Create homework08 branch and check it out
Starter Code
To help you get started, the instructor has provided you with some starter code.
# Download starter code tarball $ curl -LO https://www3.nd.edu/~pbui/teaching/cse.20289.sp18/static/tar/homework08.tar.gz # Extract starter code tarball $ tar xzvf homework08.tar.gz # Add and commit starter code $ git add homework08 $ git commit -m "homework08: starter code"
Once downloaded and extracted, you should see the following files in your
homework08 directory:
homework08
\_ Makefile # This is the Makefile for building all the project artifacts
\_ README.md # This is the README file for recording your responses
\_ duplicate.h # This is the C99 header file for the duplicate utility
\_ duplicate_main.c # This is the C99 source file for the duplicate main function
\_ duplicate_options.c # This is the C99 source file for the duplicate options functions
\_ search.h # This is the C99 header file for the search utility
\_ search_filter.c # This is the C99 source file for the search filter functions
\_ search_main.c # This is the C99 source file for the search main function
\_ search_options.c # This is the C99 source file for the search options functions
\_ search_utilities.c # This is the C99 source file for the search utility functions
\_ search_walk.c # This is the C99 source file for the search walk function
\_ test_duplicate.sh # This is the Shell test script for the duplicate utility
\_ test_search.sh # This is the Shell test script for the search utility
File: Makefile
Before you implement any of the utilities, you should first complete the
provided Makefile. Remeber, the Makefile contains all the rules or
recipes for building the project artifacts (e.g. duplicate, search,
etc.). Although the provided Makefile contains most of the variable
definitions and test recipes, you must add the appropriate rules for
duplicate, search, and any intermediate objects. The dependencies for
these targets are shown in the DAG below:
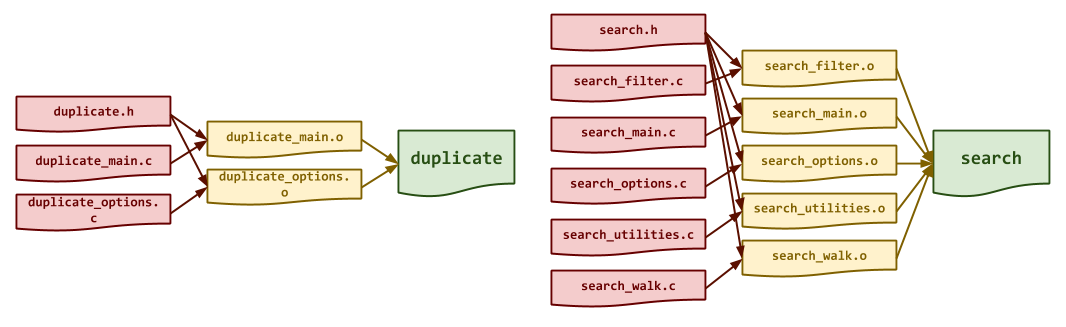
Makefile Variables
You must use the CC, CFLAGS, LD, LDFLAGS, AR, and ARFLAGS
variables when appropriate in your rules.
Moreover, since there are a lot of object files, it is recommend that you
use a pattern rule for compiling *.c files into *.o files (rather than
explicitly specifying each object rule).
Once you have a working Makefile, you should be able to run the following
commands:
$ make # Build all targets Compiling duplicate_main.o... Compiling duplicate_options.o... Linking duplicate... Compiling search_main.o... Compiling search_filter.o... Compiling search_options.o... Compiling search_utilities.o... Compiling search_walk.o... Linking search... $ make clean # Clean targets and intermediate files Cleaning... $ make -n # Simulate build with tracing output echo Compiling duplicate_main.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o duplicate_main.o -c duplicate_main.c echo Compiling duplicate_options.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o duplicate_options.o -c duplicate_options.c echo Linking duplicate... gcc -L. -o duplicate duplicate_main.o duplicate_options.o echo Compiling search_main.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o search_main.o -c search_main.c echo Compiling search_filter.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o search_filter.o -c search_filter.c echo Compiling search_options.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o search_options.o -c search_options.c echo Compiling search_utilities.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o search_utilities.o -c search_utilities.c echo Compiling search_walk.o... gcc -g -gdwarf-2 -Wall -Werror -std=gnu99 -fPIC -o search_walk.o -c search_walk.c echo Linking search... gcc -L. -o search search_main.o search_filter.o search_options.o search_utilities.o search_walk.o $ make test # Run all tests ...
Depending on your compiler, you may see some warnings with the initial starter code. Likewise, the test programs will all fail in some fashion.
Warnings
You must include the -Wall flag in your CFLAGS when you compile. This
also means that your code must compile without any warnings, otherwise points
will be deducted.
The details on what you need to implement are described in the following sections.
Activity 1: Duplicate Utility (4.5 Points)
As mentioned above, the first utility you are to implement is called
duplicate, which is a clone of the dd command. This program allows users
to copy data from one input file (ie. if) to another output file (ie. of)
while specifying parameters such as the block size (ie. bs) to use, the
number of blocks to copy (ie. count), and whether or not to skip blocks
before reading from the input file (ie. skip) or before writing to the
output file (ie. seek).
Unlike in previous assignments, the programs in this homework are not easily compartmentalized. This means that there are a lot of inter-dependencies between the functions. For instance, in order to know which file to open as the input file, the command-line options must be parsed first. However, since there are a lot of command-line options, it would be tedious to complete all the command-line parsing before actually using those options in other functions. Therefore, do not treat the following descriptions as sequential Tasks. Instead read through all the descriptions and then create a plan of attack that builds the solution piece-by-piece.
Iterative and Incremental Development
Do not try to implement everything at once. Instead, approach this program with the iterative and incremental development mindset and slowly build pieces of your application one feature at a time:
-
Implement parsing one command-line option.
-
Implement using that command-line option.
-
Repeat!
Focus on one thing at a time and feel free to write small test programs to try things out.
File: duplicate.h
The duplicate.h file is the header file for duplicate utility. In
addition to the function prototypes, this header defines the following
types:
#define DEFAULT_BYTES 512
The
DEFAULT_BYTESconstant is to be used if the user doesn't specify a block size (ie.bs).
typedef struct { char * input_file; /* Path to input file */ char * output_file; /* Path to output file */ size_t count; /* Number of blocks to copy */ size_t bytes; /* Size of each block */ size_t seek; /* Number of blocks to skip in output file */ size_t skip; /* Number of blocks to skip in input file */ } Options;
The
Optionsstruct stores the results of parsing the command-line options and contains the following attributes:
input_file: This is a string that contains the path to the input file.output_file: This is a string that contains the path to the output file.count: This is an unsigned integer that contains the number of blocks to copy.bytes: This is an unsigned integer that contains the size of each block.seek: This is an unsigned integer that contains the number of blocks to skip in the output file.skip: This is an unsigned integer that contains the number of blocks to skip in the input file.
Notes
- By default,
input_fileshould be a file that corresponds to stdin. - By default,
output_fileshould be a file that corresponds to stdout. - By default,
countshould be the largest possible integer. - By default,
bytesshould beDEFAULT_BYTES. - By default,
seekandskipshould be a value that indicates not to perform these actions.
The duplicate.h header file also defines the following macros:
#define streq(s0, s1) (strcmp((s0), (s1)) == 0)
The
streqmacro can be used to test if two strings are equal.
#define debug(M, ...) fprintf(stderr, "DEBUG %s:%d:%s: " M "\n", __FILE__, __LINE__, __func__, ##__VA_ARGS__)
The
debugmacro can be used to output debugging messages that contain the name of the file, the line number, and the function name.
File: duplicate_options.c
The duplicate_options.c file contains the C99 implementation for the
following functions:
/** * Display usage message and exit. * @param progname Name of program. * @param status Exit status. */ void usage(const char *progname, int status);
The provided
usagefunction displays the usage message and exists with the providedstatuscode.
/** * Parse command-line options. * @param argc Number of command-line arguments. * @param argv Array of command-line arguments. * @param options Pointer to Options structure. * @return Whether or not parsing the command-line options was successful. */ bool parse_options(int argc, char **argv, Options *options);
The
parse_optionsfunction parses the command-line options and sets the appropriate fields in theOptionsstructure.
Notes
File: duplicate_main.c
The duplicate_main.c file contains the C99 implementation for the main
function of the duplicate utility, which should accomplish the following:
-
Declare and initialize an
Optionsstruct with the appropriate default settings. -
Parse the command-line options.
-
Open the input file and output files.
-
Allocate a buffer with the appropriate block size.
-
Perform any skipping or seeking.
-
Copy data from the input file to the output file.
-
Clean up any allocated or requested resources.
Low-level I/O
For duplicate, you must use low-level I/O functions such as open,
read, write, lseek, and close for copying data. That is, you must
use file descriptors rather than streams for copying data. You may
continue to use streamed-based functions for printing and debugging.
File: test_duplicate.sh
As you implement duplicate, you can test it by running the test-duplicate target:
$ make test-duplicate Testing duplicate... usage ... Success usage (valgrind) ... Success no arguments ... Success no arguments (valgrind) ... Success if=/etc/passwd ... Success if=/etc/passwd (valgrind) ... Success if=asdfsadf ... Success if=asdfasdf (valgrind) ... Success if=/etc/passwd of=/tmp/duplicate.1000/of ... Success if=/etc/passwd of=/tmp/duplicate.1000/of (valgrind) ... Success if=/etc/passwd bs=2 ... Success if=/etc/passwd bs=2 (valgrind) ... Success if=/etc/passwd bs=10240 ... Success if=/etc/passwd bs=10240 (valgrind) ... Success if=/etc/passwd bs=2 count=5 ... Success if=/etc/passwd bs=5 count=5 (valgrind) ... Success if=/etc/passwd bs=2 count=5 skip=1 ... Success if=/etc/passwd bs=5 count=5 skip=1 (valgrind) ... Success if=/etc/passwd bs=2 count=5 skip=10 ... Success if=/etc/passwd bs=5 count=5 skip=10 (valgrind) ... Success if=/etc/passwd bs=2 count=5 skip=100 ... Success if=/etc/passwd bs=5 count=5 skip=100 (valgrind) ... Success if=/etc/passwd of=/tmp/duplicate.1000/of bs=2 seek=1 ... Success if=/etc/passwd of=/tmp/duplicate.1000/of bs=2 seek=1 (valgrind) ... Success if=/etc/passwd of=/tmp/duplicate.1000/of bs=2 count=5 seek=1 ... Success if=/etc/passwd of=/tmp/duplicate.1000/of bs=2 count=5 seek=1 (valgrind) ... Success Score 4.50
Note: You can always compare the behavior of your duplicate utility
directly with the actual dd command.
Activity 2: Search Utility (9 Points)
The second utility is search, which is a partial re-implementation of the
find command. Given an initial root directory, this program recursively
walks the specified path and prints out the name of any files that match the
specified criteria. For instance, only output files that are executable, the
user can specify the -executable flag:
$ ./search root -executable
For more details on what the various flags do, please consult the manual for find.
Iterative and Incremental Development
Once again, you should approach this program with the iterative and incremental development mindset and slowly build pieces of your application one feature at a time:
-
Implement parsing the root directory.
-
Implement walking the root directory.
-
Implement recursively walking the root directory.
-
Implement parsing one filter option.
-
Implement checking one filter option.
-
Repeat 4 and 5 until all options are implemented!
Remember that the goal at the end of each iteration is that you have a working program that successfully implements all of the features up to that point.
File: search.h
The search.h file is the header file for search utility. In addition to
the function prototypes, this header defines the following types:
typedef struct { int access; /* Access modes (-executable, -readable, -writable) */ int type; /* File type (-type); */ bool empty; /* Empty files and directories (-empty) */ char *name; /* Base of file name matches shell pattern (-name) */ char *path; /* Path of file matches shell pattern (-path) */ int perm; /* File's permission bits are exactly octal mode (-perm) */ time_t newer; /* File was modified more recently than file (-newer) */ int uid; /* File's numeric user ID is n */ int gid; /* File's numeric group ID is n */ } Options;
The
Optionsstruct stores the results of parsing the command-line options and contains the following attributes:
access: This is an integer that contains a bitmask for the access function.type: This is an integer that contains the file type (corresponding to thest_modefrom in the stat structure).empty: This is a boolean value that if set means only empty files and directories should be outputted.name: This is a string that contains a shell pattern each item's name should match.path: This is a string that contains a shell pattern each item's path should match.perm: This is an integer that contains permissions each item should match.newer: This is an integer that contains the timestamp each item should be newer (ie. greater) than.uid: This is an integer that contains the uid each item should match.gid: This is an integer that contains the gid each item should match.
Notes
-
Many of these attributes correspond to fields in the stat structure.
-
By default, these attributes should have values that mark the corresponding filters as disabled.
typedef bool (*FilterFunc)(const char *path, const struct stat *stat, const Options *options);
This
FilterFunctype definition specifies a function that given apathto a file, itsstatinformation, and theoptionsto the utility, returns whether or not the specified file should be excluded from the output (if so returntrue, otherwise returnfalseto indicate it should be included).
The search.h header file also defines the following macros:
#define streq(s0, s1) (strcmp((s0), (s1)) == 0)
The
streqmacro can be used to test if two strings are equal.
#define debug(M, ...) fprintf(stderr, "DEBUG %s:%d:%s: " M "\n", __FILE__, __LINE__, __func__, ##__VA_ARGS__)
The
debugmacro can be used to output debugging messages that contain the name of the file, the line number, and the function name.
File: search_options.c
The search_options.c file contains the C99 implementation for the
following functions:
/** * Display usage message and exit. * @param progname Name of program. * @param status Exit status. */ void usage(const char *progname, int status);
The provided
usagefunction displays the usage message and exists with the providedstatuscode.
/** * Parse command-line options. * @param argc Number of command-line arguments. * @param argv Array of command-line arguments. * @param root Pointer to root string. * @param options Pointer to Options structure. * @return Whether or not parsing the command-line options was successful. */ bool parse_options(int argc, char **argv, char **root, Options *options);
The
parse_optionsfunction parses the command-line options and sets the appropriate fields in theOptionsstructure.
Notes
-
The
rootcomes first, followed by any filter options. If norootis specified, then it should default to the current directory. -
You can use the
streqmacro to compare strings.
File: search_walk.c
The search_walk.c file contains the C99 implementation for the following
functions:
/** * Recursively walk the root directory with specified options. * @param root Root directory path. * @param options User specified filter options. * @return Whether or not walking this directory was successful. */ int walk(const char *root, const Options *options);
This
walkfunction recursively traverses the givenrootdirectory by checking if each item in the directory passes the specifiedOptionsfilters; if so, it simply prints out the path of the item. If the item is a directory, the function will recurse on this item before processing the next entry in its own listing.
Notes
-
You should use opendir, readdir, and closedir. Alternatively, you can use scandir, but order isn't really important.
-
You can use snprintf to build the full path of each entry.
-
Be sure to skip the current directory and parent directory when iterating through the items in each directory.
File: search_utilities.c
The search_utilities.c file contains the C99 implementation for the
following functions:
/** * Checks whether or not the directory is empty. * @param path Path to directory. * @return Whether or not the path is an empty directory. */ bool is_directory_empty(const char *path);
This
is_directory_emptyfunction returns whether or not the specifiedpathis an empty directory.
Notes
-
Be sure to account for the fact that each directory has an entry for itself and its parent.
-
If the directory does not exist, then it is not empty.
/** * Retrieves modification time of file. * @param path Path to file. * @return The modification time of the file. */ time_t get_mtime(const char *path);
The
get_mtimefunction returns the modification time of the file at the specifiedpath.
Notes
File: search_filter.c
The search_filter.c file contains the C99 implementation for the
following items:
FilterFunc FILTER_FUNCTIONS[] = { /* Array of function pointers. */ filter_access, NULL, };
The
FILTER_FUNCTIONSis aNULLterminated array of function pointers, where each item is aFilterFunc.
Notes
-
For each attribute in the
Optionsstructure, you should have a correspondingfilter_{attribute}function that checks and tests that option on a given file. For example, the providedfilter_accessfunction can be completed by doing the following:bool filter_access(const char *path, const struct stat *stat, const Options *options) { return options->access && access(path, options->access) != 0; }
This checks if
options->accessis set and if so, it returns the result of the access function on those options. -
For
nameandpath, you should use the fnmatch function to test for shell patterns. -
You are to implement a
FilterFuncfor each corresponding attribute inOptionsstructure and add it to theFILTER_FUNCTIONSarray.
/** * Filter path based on options. * @param path Path to file to filter. * @param options Pointer to Options structure. * @return Whether or not the path should be filtered out (false means include * it in output, true means exclude it from output). */ bool filter(const char *path, const Options *options);
The
filterfunction checks if the file specified bypathpasses all filters specified inoptions. The function returnstrueif the file is to be excluded from output andfalseif it is to be included in the output.
Notes
The filter function should perform an lstat on the given path and then
simply iterate through the FILTER_FUNCTIONS array. If any of the
FilterFuncs return true, then the specified file should be excluded from
the output.
This is an example of what the instructor calls the gauntlet pattern: perform a series of checks and if any fail, return immediately. If all the checks pass, then perform the final operation. This is somewhat related to what is known as the Guard Clause, which is a technique that can be used to refactor nested conditionals.
File: search_main.c
The search_main.c file contains the C99 implementation for the main
function of the search utility, which should accomplish the following:
-
Declare and initialize an
Optionsstruct with the appropriate default settings. -
Parse the command-line options.
-
Check the root directory (ie. see if it passes the filters and output its path).
-
Recursively walk the root directory.
File: test_search.sh
As you implement search, you can test it by running the test-search
target:
$ make test-search Testing search... usage ... Success usage (valgrind) ... Success no arguments ... Success no arguments (valgrind) ... Success /etc ... Success /etc (valgrind) ... Success /etc -executable ... Success /etc -executable (valgrind) ... Success /etc -readable ... Success /etc -readable (valgrind) ... Success /etc -writable ... Success /etc -writable (valgrind) ... Success /etc -type f ... Success /etc -type f (valgrind) ... Success /etc -type d ... Success /etc -type d (valgrind) ... Success /etc -name '*.conf' ... Success /etc -name '*.conf' (valgrind) ... Success /etc -path '*security/*.conf' ... Success /etc -path '*security/*.conf' (valgrind) ... Success /etc -perm 600 ... Success /etc -perm 600 (valgrind) ... Success /etc -newer /etc/hosts ... Success /etc -newer /etc/hosts (valgrind) ... Success /etc -uid 0 ... Success /etc -uid 0 (valgrind) ... Success /etc -gid 0 ... Success /etc -gid 0 (valgrind) ... Success /etc -empty ... Success /etc -empty (valgrind) ... Success /etc -type f -executable ... Success /etc -type f -executable (valgrind) ... Success /etc -type d -readable ... Success /etc -type d -readable (valgrind) ... Success /etc -type d -name '*conf*' ... Success /etc -type d -name '*conf*' (valgrind) ... Success /etc -type f -executable -readable ... Success /etc -type f -executable -readable (valgrind) ... Success /etc -perm 755 -uid 0 ... Success /etc -perm 755 -uid 0 (valgrind) ... Success Score 9.00
Note: You can always compare the behavior of your search utility
directly with the actual find command.
Activity 3: Reflection (1 Point)
Once you have working versions of duplicate and search, you are to use
the strace command to compare the system calls used by your utilities
versus those utilized by dd and find.
$ strace -c ./duplicate if=/etc/passwd > /dev/null % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 0.00 0.000000 0 3 read 0.00 0.000000 0 1 write 0.00 0.000000 0 3 close 0.00 0.000000 0 7 6 stat 0.00 0.000000 0 1 fstat 0.00 0.000000 0 4 mmap 0.00 0.000000 0 4 mprotect 0.00 0.000000 0 3 brk 0.00 0.000000 0 1 1 access 0.00 0.000000 0 1 execve 0.00 0.000000 0 1 arch_prctl 0.00 0.000000 0 10 7 openat ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000000 39 14 total
In your README.md, record the output of the strace information for
duplicate vs dd and search vs find, and then answer the following
questions:
-
Describe the differences you see between the number and type of system calls used by your utilities as compared to the standard Unix programs.
-
Did you notice anything surprising about the trace of your utilities or the trace of the standard Unix programs? Which implementations are faster or more efficient? Explain.
Guru Point: Easter Egg (1 Point)
In the spirit of the Easter Season, you are to embed an easter egg into
your search program. For instance, here is the first video game easter
egg (as discussed in History of Computing):
Here are some possible easter egg ideas:
-
Display scrolling text of credits on the project or your favorite song lyrics.
-
Play sounds or a song.
-
Display some sort of animation.
For instance, the instructor's version of search on the student
machines contains the following easter eggs:
$ ~pbui/pub/bin/search for the droid $ ~pbui/pub/bin/search for a pony $ ~pbui/pub/bin/search the matrix
To receive credit, simply demonstrate the easter egg to the instructor or a TA.
Submission
To submit your assignment, please commit your work to the homework08 folder
of your homework08 branch in your assignments GitLab repository.
Your homework08 folder should only contain the following files:
MakefileREADME.mdduplicate.hduplicate_main.cduplicate_options.csearch.hsearch_filter.csearch_main.csearch_options.csearch_utilities.csearch_walk.ctest_duplicate.shtest_search.sh
Note: Don't include any object files or executables.
#-------------------------------------------------- # BE SURE TO DO THE PREPARATION STEPS IN ACTIVITY 0 #-------------------------------------------------- $ cd homework08 # Go to Homework 07 directory ... $ git add Makefile # Mark changes for commit $ git add duplicate_*.c # Mark changes for commit $ git commit -m "homework08: duplicate" # Record changes ... $ git add Makefile # Mark changes for commit $ git add search_*.c # Mark changes for commit $ git commit -m "homework08: search" # Record changes ... $ git add README.md # Mark changes for commit $ git commit -m "homework08: README" # Record changes ... $ git push -u origin homework08 # Push branch to GitLab
Remember to create a merge request and assign the appropriate TA from the Reading 10 TA List.