This Is Not The Course Website You Are Looking For
This course website is from a previous semester. If you are currently in the class, please make sure you are viewing the latest course website instead of this old one.
Homework 06: Miles
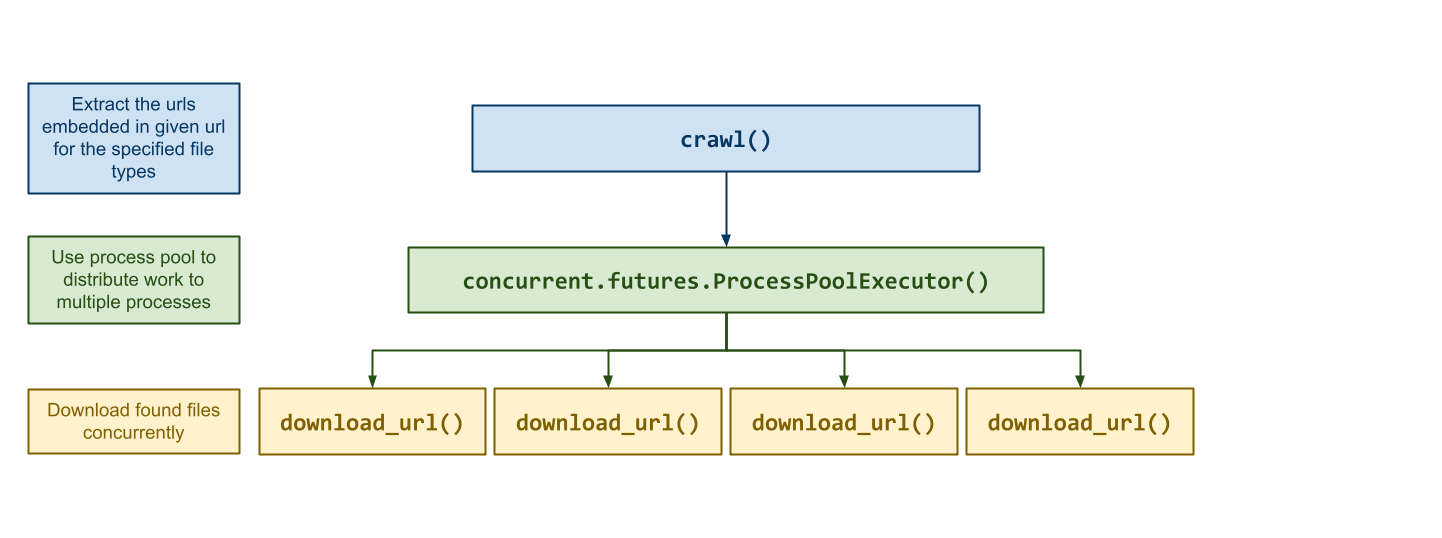
The goal of this homework assignment is to allow you to practice using functional programming to process data in Python. In this assignment, you will write a small web crawler that uses regular expressions to extract links to media files such as JPGs, PNGs, PDFs, and MP3s, and then downloads them concurrently using a process pool.
By using functional programming to structure your application in a concurrent manner, you will be able to take advantage of multiple CPU cores to execute the program in parallel.
For this assignment, record your scripts and any responses to the following
activities in the homework06 folder of your assignments GitHub
repository and push your work by noon Saturday, March 9.
Activity 0: Preparation¶
Before starting this homework assignment, you should first perform a git
pull to retrieve any changes in your remote GitHub repository:
$ cd path/to/repository # Go to assignments repository
$ git switch master # Make sure we are in master branch
$ git pull --rebase # Get any remote changes not present locally
Next, create a new branch for this assignment:
$ git checkout -b homework06 # Create homework06 branch and check it out
Task 1: Skeleton Code¶
To help you get started, the instructor has provided you with the following skeleton code:
# Go to homework06 folder
$ cd homework06
# Download Makefile
$ curl -LO https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/txt/homework06/Makefile
# Download Python skeleton code
$ curl -LO https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/txt/homework06/miles.py
Once downloaded, you should see the following files in your homework06 directory:
homework06
\_ Makefile # This is the Makefile building all the assignment artifacts
\_ miles.py # This is the Python script for the miles script
DocTests¶
You may notice that in addition to the usual comments and TODOs, the
docstrings of each method also contains a few doctests.
You are not to modify these doctests and must keep them in-place. They are used to verify the correctness of your code.
Your code goes below the docstrings, where the TODO and pass
commands are (you may remove the pass once you complete the method).
Task 2: Initial Import¶
Now that the files are downloaded into the homework06 folder, you can
commit them to your git repository:
$ git add Makefile # Mark changes for commit
$ git add *.py
$ git commit -m "Homework 06: Initial Import" # Record changes
Task 3: Unit Tests¶
After downloading these files, you can run the make command to run the
tests.
# Run all tests (will trigger automatic download)
$ make
You will notice that the Makefile downloads these additional test data and scripts:
homework06
\_ miles.test # This is the Python test for the miles script
In addition to the embedded doctests in the skeleton code, you will be using these unit tests to verify the correctness and behavior of your code.
Automatic Downloads¶
The test scripts are automatically downloaded by the Makefile, so any
modifications you do to them will be lost when you run make again. Likewise,
because they are automatically downloaded, you do not need to add or commit
them to your git repository.
The details on what you need to implement for this assignment are described in the following sections.
Frequently Asked Questions¶
Activity 1: Miles (10 Points)¶
For the first activity, you are to write a script called miles.py, which
acts a small web crawler that does the following:
-
Extract URLs:
miles.pywill scan a given website for specified media files such as JPGs, MP3s, PDFs, and PNGs using regular expressions. -
Process Pool:
miles.pywill take advantage of functional programming and a process pool to distribute the found media files to multiple processes. -
Download URLs:
miles.pywill download the found media files concurrently to a destination folder.
With this script, you can crawl a website and extract any interesting media assets in parallel!
# Make script executable
$ chmod +x ./miles.py
# Display usage
$ ./miles.py -h
Usage: miles.py [-d DESTINATION -n CPUS -f FILETYPES] URL
Crawl the given URL for the specified FILETYPES and download the files to the
DESTINATION folder using CPUS cores in parallel.
-d DESTINATION Save the files to this folder (default: .)
-n CPUS Number of CPU cores to use (default: 1)
-f FILETYPES List of file types: jpg, mp3, pdf, png (default: all)
Multiple FILETYPES can be specified in the following manner:
-f jpg,png
-f jpg -f png
# Download jpg and pngs from course website to downloads destination folder using 4 CPUs
$ ./miles.py -d downloads -f jpg,png -n 4 https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/
Downloading https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/img/tlcl.jpg...
Downloading https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/img/ostep.jpg...
Downloading https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/img/logo.png...
Downloading https://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/img/automate.png...
Files Downloaded: 4
Bytes Downloaded: 0.23 MB
Elapsed Time: 0.43 s
Bandwidth: 0.54 MB/s
The miles.py script takes the following possible arguments:
-
-d: This allows the user to set theDESTINATIONfolder where it should save downloaded media files. If this directory does not exist, then the script should create it. -
-n: This allows the user to set the number ofCPUs(ie. processes) to use when downloading the media files concurrently. -
-f: This allows the user to set whichFILETYPESto extract. The script must support: JPGs, MP3s, PDFs, and PNGs. If noFILETYPESare specified, then all of them will be extracted. -
-h: This prints the usage message and exits with success.
After these flags, the remaining argument is the URL to crawl.
If an unsupported flag is specified, or if no URL is given, then miles.py
should print out the usage message and exit with failure.
Task 1: miles.py¶
To implement the miles.py Python script, you will need to complete the
following functions:
-
resolve_url(base: str, url: str) -> strThis function resolves a
urlgiven abaseURL.Many websites will utilize relative URLs such as
static/img/homework06-miles.png. These relative URLs need to be expanded or resolved to absolute URLs given a base.For instance, the relative URL
static/img/homework06-miles.pngon this page should resolve tohttps://www3.nd.edu/~pbui/teaching/cse.20289.sp24/static/img/homework06-miles.pngsince the base ishttps://www3.nd.edu/~pbui/teaching/cse.20289.sp24/homework06.htmlHint: You can use urllib.parse.urljoin with the
baseif the givenurlis not already an absolute URL (ie. has://).extract_urls(url: str, file_types: list[str]) -> Iterator[str]This function extracts the urls of the specified
file_typesfrom the givenurlandyieldsthem one at a time.To implement this function you will need to fill in the
FILE_REGEXdict at the top of the script. This dict should hold a mapping fromfile_typeto a list of regular expressions that can be used with re.findall to extract the URL corresponding to the media type.Hints:
-
Use
requests.getto retrieve the HTML of the givenurl. Be sure to check for any errors. -
Use re.findall with the appropriate
file_typesregular expressions on the contents of the response to find the corresponding medial URLs. -
You must support the following patterns:
File Type Patterns JPG <img src="path.jpg">,<a href="path.jpg">MP3 <audio src="path.mp3">,<a href="path.mp3">PDF <a href="path.pdf">PNG <img src="path.png">,<a href="path.png">Your regular expressions will need account of variations in spaces and different HTML attributes, as well as the presence or absence of quotes around the URL.
Here is an example regular expression for the PDFs:
r'<a.*href="?([^\" ]+.pdf)' -
Use
yieldwithresolve_urlto generate absolute URLs.
download_url(url: str, destination: str=DESTINATION) -> Optional[str]This function downloads the media asset specified by
urlto thedestinationdirectory and returns the path to this new file.Hints:
-
Print the message
Downloading {url}...at the top of the function to inform the user what is being downloaded. -
Use
requests.getto retrieve the contents of the givenurl. Be sure to check for any errors (ie. if the status code is not200). -
Use os.path.basename to get the name of the file based on the
urland create a new path with os.path.join with thedestinationand this name. -
Using
withand open in write and binary mode to create the file you wish to store the contents of the response into.
crawl(url: str, file_types: list[str], destination: str=DESTINATION, cpus: int=CPUS) -> NoneThis function crawls the specified
urlby extracting the urls for the specifiedfile_typesand then uses a process pool to download the found media assets concurrently to thedestinationfolder using multiplecpus.At the end of the function, it will print out the following information:
- The number of files successfully downloaded.
- The number of bytes downloaded to the destination folder (
megabytes). - The elapsed time required to crawl the site (
seconds). - The estimated bandwidth based on the bytes downloaded and the elapsed time (
MB/s).
Hints:
-
Use time.time to create timestamps to keep track of your start and end times.
-
Use concurrent.futures.ProcessPoolExecutor to create a process pool.
-
Use os.stat get the size of each of the downloaded files in
destination
See the FAQ slides for a more extensive outline and example of how to use the
mapfunction in the concurrent.futures.ProcessPoolExecutor.main(arguments=sys.argv[1:]) -> NoneThis function processes the command line
arguments, crawls the givenURLfor the specifiedFILETYPES, and downloads the found media assets to theDESTINATIONfolder usingCPUsprocesses.Task 2: Testing¶
As you implement
miles.py, you can use the provided doctests to verify the correctness of your code:# Run doctests $ python3 -m doctest miles.py -v ... 2 items had no tests: miles miles.usage 5 items passed all tests: 4 tests in miles.crawl 6 tests in miles.download_url 3 tests in miles.extract_urls 4 tests in miles.main 3 tests in miles.resolve_url 20 tests in 7 items. 20 passed and 0 failed. Test passed.You can also use
maketo run both the doctests and the unit tests:# Run unit tests (and doctests) $ make test-miles Testing miles... test_00_doctest (__main__.MilesTest) ... ok test_01_mypy (__main__.MilesTest) ... ok test_02_resolve_url (__main__.MilesTest) ... ok test_03_extract_urls (__main__.MilesTest) ... ok test_04_download_url (__main__.MilesTest) ... ok test_05_crawl_single (__main__.MilesTest) ... ok test_06_crawl_multi (__main__.MilesTest) ... ok test_07_main_usage (__main__.MilesTest) ... ok test_08_main_destination (__main__.MilesTest) ... ok test_09_main_destination_filetypes (__main__.MilesTest) ... ok test_10_main_destination_filetypes_cpus (__main__.MilesTest) ... ok test_11_script_strace (__main__.MilesTest) ... ok Score 10.00 / 10.00 Status Success ---------------------------------------------------------------------- Ran 11 tests in 30.277s OKTo just run the unit tests, you can do the following:
# Run unit tests $ ./miles.test -v ...To run a specific unit test, you can specify the method name:
# Run only mypy unit test $ ./miles.test -v MilesTest.test_01_mypy ...To manually check your types, you can use mypy:
# Run mypy to check types $ mypy miles.pyActivity 3: Quiz (1 Point)¶
Once you have completed all the activities above, you are to complete the following reflection quiz:
As with Reading 01, you will need to store your answers in a
homework06/answers.jsonfile. You can use the form above to generate the contents of this file, or you can write the JSON by hand.To test your quiz, you can use the
check.pyscript:$ ../.scripts/check.py Checking homework06 quiz ... Q01 0.20 Q02 0.20 Q03 0.10 Q04 0.20 Q05 0.30 Score 1.00 / 1.00 Status SuccessGuru Point (1 Extra Credit Point)¶
For extra credit, you are to make your own personal website such as:
To do so, you can use a platform such as GitHub Pages or use resources from the GitHub Student Developer Pack (which includes cloud and domain name credits).
Verification¶
To get credit for this Guru Point, share the link to your personal website to a TA to verify. You have up until a week after this assignment is due to verify your Guru Point.
Self-Service Extension¶
Remember that you can always forgo this Guru Point for two extra days to do the homework. That is, if you need an extension, you can simply skip the Guru Point and you will automatically have until Monday to complete the assignment for full credit.
Just leave a note on your Pull Request of your intentions.
Submission (11 Points)¶
To submit your assignment, please commit your work to the
homework06folder of yourhomework06branch in your assignments GitHub repository. Your homework06 folder should only contain the following files:- Makefile
- answers.json
- miles.py
Note: You do not need to commit the test scripts because the
Makefileautomatically downloads them.#----------------------------------------------------------------------- # Make sure you have already completed Activity 0: Preparation #----------------------------------------------------------------------- ... $ git add miles.py # Mark changes for commit $ git commit -m "Homework 06: Activity 1 completed" # Record changes ... $ git add answers.json # Mark changes for commit $ git commit -m "Homework 06: Activity 2 completed" # Record changes ... $ git push -u origin homework06 # Push branch to GitHubPull Request¶
Remember to create a Pull Request and assign the appropriate TA from the Reading 07 TA List.
DO NOT MERGE your own Pull Request. The TAs use open Pull Requests to keep track of which assignments to grade. Closing them yourself will cause a delay in grading and confuse the TAs.