Homework 08: Python, OOP
The goal of this homework assignment is to introduce you to programming in
Python, particularly using data structures such as lists, sets, and
dicts and employing object-oriented programming principles such as
encapsulation, inheritance, and polymorphism. To do so, you will first
implement a priority queue class and then use it to solve a programming
challenge using a greedy algorithm. After this, you will write your own
spell checker with different database types.
For this assignment, you are to do your work in the homework08 folder of
your assignments GitHub repository and push your work by noon
Wednesday, November 1.
Activity 0: Preparation¶
Before starting this homework assignment, you should first perform a git
pull to retrieve any changes in your remote GitHub repository:
$ cd path/to/repository # Go to assignments repository
$ git switch master # Make sure we are in master branch
$ git pull --rebase # Get any remote changes not present locally
Next, create a new branch for this assignment:
$ git checkout -b homework08 # Create homework08 branch and check it out
Task 1: Skeleton Code¶
To help you get started, the instructor has provided you with the following skeleton code:
# Go to assignments repository
$ cd path/to/assignments/repository
# -----------------------------------------------------
# MAKE SURE YOU ARE NOT INSIDE THE homework08 DIRECTORY
# -----------------------------------------------------
# MAKE SURE YOU ARE AT THE TOP-LEVEL DIRECTORY
# -----------------------------------------------------
# Download skeleton code tarball
$ curl -LO https://www3.nd.edu/~pbui/teaching/cse.20312.fa23/static/tar/homework08.tar.gz
# Extract skeleton code tarball
$ tar xzvf homework08.tar.gz
Once downloaded and extracted, you should see the following files in your
homework08 directory:
homework08
\_ Makefile # This is the Makefile for building all the project artifacts
\_ cups.py # This is the Python script for the Cups programming challenge
\_ priority_queue.py # This is the Python script for the Priority Queue data structure
\_ spell_check.py # This is the Python script for the Spell Check application
\_ spell_check_benchmark.py # This is the Python script for the benchmarking the Spell Check application
Task 2: Initial Import¶
Now that the files are extracted into the homework08 folder, you can
commit them to your git repository:
# Go into homework08 folder
$ cd homework08
# Add and commit initial skeleton files
$ git add Makefile # Mark changes for commit
$ git add *.py
$ git commit -m "Homework 08: Initial Import" # Record changes
Task 3: Unit Tests¶
After downloading and extracting these files, you can run the make command
to run the tests.
# Run all tests (will trigger automatic download)
$ make
You will notice that the Makefile downloads three additional test scripts:
homework08
\_ cups_test.py # This is the Python unit test for the Cups programming challenge
\_ priority_queue_test.py # This is the Python unit test for the Priority Queue data structure
\_ spell_check_test.py # This is the Python unit test for the Spell Check application
In addition to the embedded doctests in the skeleton code, you will be using these unit tests to verify the correctness and behavior of your code.
Automatic Downloads¶
The test scripts are automatically downloaded by the Makefile, so any
modifications you do to them will be lost when you run make again.
Likewise, because they are automatically downloaded, you do not need to add
or commit them to your git repository.
The details on what you need to implement for this assignment are described in the following sections.
Activity 1: Priority Queue (3 Points)¶
For the first activity, you are to implement a priority queue class. Likew
a stack or queue, a priority queue has both a push and pop
operation:
push(value): This adds thevalueto the priority queue.pop(): This removes the largestvaluefrom the priority queue.
To facilitate an efficient pop operation, you will be implementing a
priority queue which uses a sorted list internally as show below.

Task 1: priority_queue.py¶
The priority_queue.py Python script contains the priority queue class
you are to complete for this activity. You will need to implement the
following methods in the PriorityQueue:
-
__init__(self, data=None):This constructor method initializes the internal
dataattribute. -
push(self, value):This method adds a
valueto thePriorityQueue. -
pop(self):This method removes the largest value from the
PriorityQueue.Hint: Consider where the largest value is guaranteed to be located in the internaldatalist. -
front(self):This property returns the largest value in the
PriorityQueue -
empty(self):This property returns whether or not the
PriorityQueuehas any values.Hint: Remember that Python has a notion of truthiness. -
__len__(self):This magic method returns the number of values in the
PriorityQueue.
DocTests¶
You may notice that in addition to the usual comments and TODOs, the docstrings of each method also contains a few doctests.
You are not to modify these doctests and must keep them in-place. They are used to verify the correctness of your code.
Your code goes below the docstrings, where the TODO and pass commands are (you may remove the pass once you complete the method).
Task 2: Testing¶
As you implement priority_queue.py, you can use the provided doctests to
verify the correctness of your code:
# Run doctests
$ python3 -m doctest priority_queue.py -v
...
6 items passed all tests:
4 tests in priority_queue.PriorityQueue.__init__
2 tests in priority_queue.PriorityQueue.__len__
2 tests in priority_queue.PriorityQueue.empty
2 tests in priority_queue.PriorityQueue.front
2 tests in priority_queue.PriorityQueue.pop
3 tests in priority_queue.PriorityQueue.push
15 tests in 8 items.
15 passed and 0 failed.
Test passed
You can also use make to run both the doctests and the unit tests:
# Run unit tests (and doctests)
$ make test-priority-queue
Testing PriorityQueue ...
test_00_doctest (__main__.PriorityQueueTest) ... ok
test_01_constructor (__main__.PriorityQueueTest) ... ok
test_02_push (__main__.PriorityQueueTest) ... ok
test_03_pop (__main__.PriorityQueueTest) ... ok
test_04_front (__main__.PriorityQueueTest) ... ok
test_05_empty (__main__.PriorityQueueTest) ... ok
test_06_len (__main__.PriorityQueueTest) ... ok
Score 3.00 / 3.00
Status Success
----------------------------------------------------------------------
Ran 7 tests in 0.002s
OK
To just run the unit tests, you can do the following:
# Run unit tests
$ ./priority_queue_test.py -v
...
To run a specific unit test, you can specify the method name:
# Run only push unit test
$ ./priority_queue_test.py -v PriorityQueueTest.test_02_push
...
Iterative Development¶
You should practice iterative development. That is, rather than writing a bunch of code and then debugging it all at once, you should concentrate on one function at a time and then test that one thing at a time. The provided unit tests allow you to check on the correctness of the individual functions without implementing everything at once. Take advantage of this and build one thing at a time.
Activity 2: Cups (2 Points)¶
Once you have completed the PriorityQueue class from Activity 1, you
are to use it to solve the following programming challenge:
Because of the questionable quality of the tap water in Fitzpatrick, the CSE department has added a new water dispenser to the CSE Commons that is capable of dispensing cold, warm, and hot water. The new machine is a bit strange though, because every second, it can fill up
2cups with different types of water or just1cup of any type of water.Since MD now resides in the CSE Commons, he is tired of seeing students line up in front of his office trying to fill up all their water cups. He desperately wants you to write a program that, given the number of cold, water, and hot water cups students want to fill, determine the minimum number of seconds needed to fill up all the cups.
For instance, suppose students wanted to fill up
1cold,4warm, and2hot water cups. This could be accomplished in4seconds:
Fill up a warmw cup and hot cup.
Fill up a warm cup and cold cup.
Fill up a warm cup and hot cup.
Fill up a warm cup.
After some thinking, you realize that you can use a greedy algorithm with
your PriorityQueue from Activity 1 to solve this problem and set off to
do so and make MD a happy sysadmin.
Task 1: cups.py¶
To solve this problem, you are to complete the cups.py Python script by
implementing the following functions:
-
fill_cups(cups):This function uses your
PriorityQueueto implement a greedy algorithm that attempts to fill two types of cup at a time until there is only one remaining type in order to determine the minimum number of seconds required to fill all cups of water. -
main(stream=sys.stdin):This function reads one line of input (representing the types of cups of water to fill) from the given stream at a time, calls the
fill_cupsfunction on the cups, and then prints the minimum number of seconds required to fill those cups.
Hints¶
-
Remember that you can iterate through a stream of input using a
forloop:for line in stream: pass -
To break up a string into individual words, you can use [str.split]:
words = 'out of style'.split() # ['out', 'of', 'style'] -
To convert a sequence of strings into integers, you can do either of the following:
ints = list(map(int, strings)) ints = [int(s) for s in strings]
Task 2: Testing¶
As you implement cups.py, you can use the provided doctests to verify the
correctness of your code:
# Run doctests
$ python3 -m doctest cups.py -v
...
2 items passed all tests:
3 tests in cups.fill_cups
2 tests in cups.main
5 tests in 3 items.
5 passed and 0 failed.
Test passed.
You can also use make to run both the doctests and the unit tests:
# Run unit tests (and doctests)
$ make test-cups
Testing Cups...
test_00_doctest (__main__.CupsTest) ... ok
test_01_fill_cups (__main__.CupsTest) ... ok
test_02_main (__main__.CupsTest) ... ok
Score 2.00 / 2.00
Status Success
----------------------------------------------------------------------
Ran 3 tests in 0.001s
OK
To just run the unit tests, you can do the following:
# Run unit tests
$ ./cups_test.py -v
...
To run a specific unit test, you can specify the method name:
# Run only fill_cups unit test
$ ./cups_test.py -v CupsTest.test_01_fill_cups
...
Activity 3: Spell Check (5 Points)¶
For the third activity, you are to implement a spell checker that reads
text from standard input and checks if each word in the text appears in a
WordsDatabase (if not, then the word is considered mispelled and is
printed out). To implement the WordsDatabase, you are to load all the words
in the file /usr/share/dict/words (present on most Unix machines) into
one of the following WordsDatabase classes:
WordsList: This stores the words in an internaldatalist.WordsSet: This stores the words in an internaldataset.WordsDict: This stores the words in an internaldatadict.
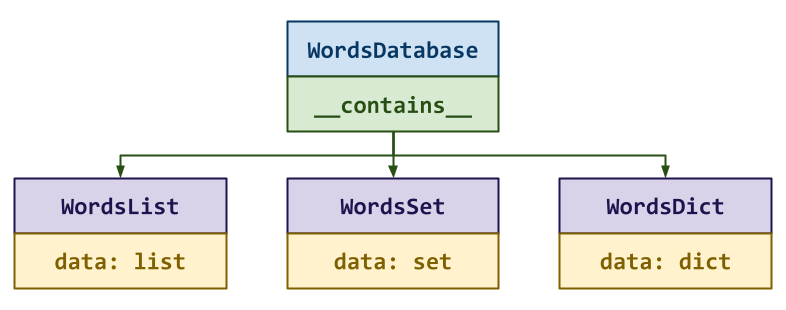
As shown above, each of these WordDatabase classes derives from a parent
WordDatabase class that provides the __contains__ method which searches
the internal data using the in operator.
Task 1: spell_check.py¶
The spell_check.py Python script contains the WordsDatabase classes you
are to complete for this activity. You will need to implement the following
methods:
-
WordsDatabase.__contains__(self, target):This is the magic method which returns whether or not the
targetis in the internaldatacollection.Hint: Consider using theinoperator. -
WordsList.__init__(self, path=WORDS_PATH):This constructor loads the words in the file specified by
pathinto an internaldatalist. -
WordsSet.__init__(self, path=WORDS_PATH):This constructor loads the words in the file specified by
pathinto an internaldataset. -
WordsDict.__init__(self, path=WORDS_PATH):This constructor loads the words in the file specified by
pathinto an internaldatadict.Hint: To read data from a file, you can use the following pattern:with open(path) as stream: for line in stream: passThe
withstatement will open the file specified bypathand bind the file to thestreamvariable. Once thewithstatement is complete, it will automatically close the file for you.
Once you have implemented these WordsDatabase classes, you will need to
implement the main function:
-
main(arguments=sys.argv[1:], stream=sys.stdin):This function parses the command line
argumentsand then checks each word in the inputstreamto see if it is theWordsDatabase:- Load appropriate Words Database (based on the
arguments) - Read each line from the
stream. - Check each word from each line.
- Print any words that are not in the Words Database.
If the user specifies
-d, then you should use theWordsDictas theWordsDatabase. Likewise, if the user specifies-l, then you should use theWordsListas theWordsDatabase. Finally, if the user specifies-s, then you should use theWordsSetas theWordsDatabase.Hint: To parse the command line arguments, you use the following pattern:try: words = WORDS_DATABASES[arguments[0]]() except (KeyError, IndexError): words = WordsList()This will attempt to lookup the first argument
arguments[0]in theWORDS_DATABASESdict. If it is there, it will return the name of aWordsDatabaseclass and then call it to initialize thewordsvariable. If there is no argument (IndexError) or the argument does not exist in theWORDS_DATABASESdict (KeyError), thenwordswill useWordsListby default. - Load appropriate Words Database (based on the
Task 2: Testing¶
As you implement spell_check.py, you can use the provided doctests to verify the
correctness of your code:
# Run doctests
$ python3 -m doctest spell_check.py -v
...
4 items passed all tests:
4 tests in spell_check.WordsDict.__init__
4 tests in spell_check.WordsList.__init__
4 tests in spell_check.WordsSet.__init__
4 tests in spell_check.main
16 tests in 10 items.
16 passed and 0 failed.
Test passed.
You can also use make to run both the doctests and the unit tests:
# Run unit tests (and doctests)
$ make test-spell-check
Testing SpellCheck ...
test_00_doctest (__main__.SpellCheckTest) ... ok
test_01_word_list (__main__.SpellCheckTest) ... ok
test_02_word_set (__main__.SpellCheckTest) ... ok
test_03_word_dict (__main__.SpellCheckTest) ... ok
test_04_main_default (__main__.SpellCheckTest) ... ok
test_05_main_list (__main__.SpellCheckTest) ... ok
test_06_main_set (__main__.SpellCheckTest) ... ok
test_07_main_dict (__main__.SpellCheckTest) ... ok
Score 5.00 / 5.00
Status Success
----------------------------------------------------------------------
Ran 8 tests in 0.261s
OK
To just run the unit tests, you can do the following:
# Run unit tests
$ ./spell_check_test.py -v
...
To run a specific unit test, you can specify the method name:
# Run only WordList unit test
$ ./spell_check_test.py -v SpellCheckTest.test_01_word_list
...
Activity 4: Quiz (2 Points)¶
Once you have completed all the activities above, you are to complete the following reflection quiz:
As with Reading 01, you will need to store your answers in a
homework08/answers.json file. You can use the form above to generate the
contents of this file, or you can write the JSON by hand.
To check your quiz directly, you can use the check.py script:
$ ../.scripts/check.py
Checking homework08 quiz ...
Q1 0.40
Q2 0.10
Q3 0.20
Q4 0.40
Q5 0.30
Q6 0.10
Q7 0.10
Q8 0.20
Q9 0.20
Score 2.00 / 2.00
Status Success
Leet Point (1 Extra Credit Point)¶
For extra credit, you are to solve the following LeetCode problem in Python.
To receive credit, you must pass on LeetCode and achieve an Accepted submission.
Verification¶
To get credit for this Leet Point, show your solution and the LeetCode acceptance page to a TA to verify (or attached a screenshot with both to your Pull Request). You have up until two days after this assignment is due to verify your Leet Point.
Self-Service Extension¶
Remember that you can always forgo this Leet Point for two extra days to do the homework. That is, if you need an extension, you can simply skip the Leet Point and you will automatically have until Friday to complete the assignment for full credit.
Just leave a note on your Pull Request of your intentions.
Submission¶
To submit your assignment, please commit your work to the homework08 folder
of your homework08 branch in your assignments GitHub repository:
#-----------------------------------------------------------------------
# Make sure you have already completed Activity 0: Preparation
#-----------------------------------------------------------------------
...
$ git add priority_queue.py # Mark changes for commit
$ git commit -m "Homework 08: Activity 1" # Record changes
...
$ git add cups.py # Mark changes for commit
$ git commit -m "Homework 08: Activity 2" # Record changes
...
$ git add spell_check.py # Mark changes for commit
$ git commit -m "Homework 08: Activity 3" # Record changes
...
$ git add answers.json # Mark changes for commit
$ git commit -m "Homework 08: Activity 4" # Record changes
...
$ git push -u origin homework08 # Push branch to GitHub
Pull Request¶
Remember to create a Pull Request and assign the appropriate TA from the Reading 09 TA List.
DO NOT MERGE your own Pull Request. The TAs use open Pull Requests to keep track of which assignments to grade. Closing them yourself will cause a delay in grading and confuse the TAs.