Project 02: Process Queue
Overview
The second project is to build a multi-core process queue called pq,
whose purpose is to receive a series of jobs and then schedule them to run
on multiple CPU cores as separate processes.
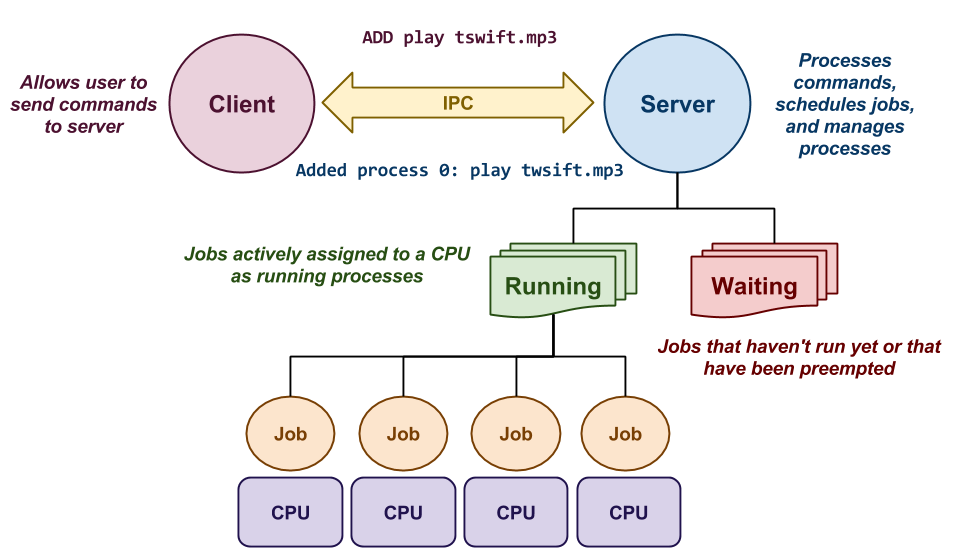
This process queue has two components as shown above:
-
Client: This component allows the user to send the following commands to the server:
-
Add: This adds a command to the waiting queue on the server.
-
Status: This retrieves and displays the status of the queue.
-
Running: This retrieves and displays just the running jobs in the queue.
-
Waiting: This retrieves and displays just the waiting jobs in the queue.
-
Flush: This removes all the jobs from the queue (and terminates any active processes).
-
-
Server: This component maintains of a queue of running jobs (ie. tasks that actively assigned CPU time), and waiting jobs (ie. tasks that haven't started yet or have been preempted). Its purpose is to schedule as many running jobs as there are CPU cores using one of the three scheduling policies mentioned below.
The number of CORES and the scheduling policy can be specified by the user when the server is started, but cannot change once it is active. By default, the server assumes one core and the FIFO scheduling policy.
Working in groups of one or two people, you are to create this pq
application by midnight on Tuesday, September 26, 2017. More
details about this project and your deliverables are described below.
Balancing the Load
While it is unlikely that you will write an operating system scheduler in your career, you may need to implement or at least interact with things like load balancers or batch queues, especially in parallel or distributed environments such as the cloud.
For instance, many websites use Cloudflare which performs load balance to prevent denial-of-service attacks. Similarly, we have used HTCondor in the past to schedule many jobs on the distributed computing cluster at Notre Dame. In both of these situations some decision making is required to map jobs to a particular set of resources.
This project will allow to explore the challenges in this type of decision making by having you implementing and test different types of scheduling policies for a process queue.
Protocol
To communicate, the client and server must use a common IPC mechanism such as named pipes or Unix domain sockets (which one is up to you).
The communication will be a simple text-based request and respond protocol that works as follows:
| Client Requests | Example | Server Responds | Example |
|---|---|---|---|
| ADD command | ADD play tswift.mp3 | Reports added process | Added process 0: play tswift.mp3 |
| STATUS | STATUS | Summary of sizes of runnning and waiting queues, average turnaround and response times, and the jobs in all queues. |
Running = 1, Waiting = 8, Levels = 0, Turnaround = 00.10, Response = 00.00
Running Queue:
PID COMMAND STATE USER THRESHOLD USAGE ARRIVAL START
2309 ./worksim.py 0.1 1 Sleeping 100 0 20.75 1505531908 1505531909
Waiting Queue:
PID COMMAND STATE USER THRESHOLD USAGE ARRIVAL START
0 ./worksim.py 0.1 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.5 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.5 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.5 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
|
| RUNNING | RUNNING | Lists all jobs in running queue. |
PID COMMAND STATE USER THRESHOLD USAGE ARRIVAL START
2309 ./worksim.py 0.1 1 Sleeping 100 0 20.75 1505531908 1505531909
|
| WAITING | WAITING | Lists all jobs in waiting queue. |
PID COMMAND STATE USER THRESHOLD USAGE ARRIVAL START
0 ./worksim.py 0.1 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.5 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.5 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.5 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
0 ./worksim.py 0.9 1 Sleeping 0 0 0.00 1505531908 0
|
| FLUSH | FLUSH | Removes all jobs from all queues (terminates any that are active or suspended). |
Flushed 1 running and 8 waiting processes
|
Each message should be terminated with a newline character (ie. \n).
Likewise, the server only needs to process one command per client and
only needs to handle one client at a time. The client should echo the
response it receives from the server to stdout.
Scheduling
The order in which jobs should be executed is determined by one of the following scheduling policies:
-
FIFO: Execute jobs in the order in each they arrival in the process queue.
-
Round Robin: Execute jobs in a round robin fashion.
-
Multi-Level Feedback Queue: Execute jobs based on a dynamic priority structure.
You must implement all three scheduling disciplines along with any accounting and preemption mechanims required to build these algorithms.
Usage
The full set of pq command-line options are show below:
$ ./pq -h
Usage: ./pq [options]
General Options:
-h Print this help message
-f PATH Path to IPC channel
Client Options:
add COMMAND Add COMMAND to queue
status Query status of queue
running Query running jobs
waiting Query waiting jobs
flush Remove all jobs from queue
Server Options:
-n NCPUS Number of CPUs
-p POLICY Scheduling policy (fifo, rdrn, mlfq)
-t MICROSECONDS Time between scheduling
For instance, to start the server with 4 cores and with the Round Robin
scheduling policy, we would run:
$ ./pq -n 4 -p rdrn
To add the command echo DOING_IT_FOR_THE_MONEY to the queue, we would use
the client as follows:
$ ./pq add echo DOING_IT_FOR_THE_MONEY
Reference Implementation
A reference implementation of pq can be found on AFS:
/afs/nd.edu/user15/pbui/pub/bin/pq
Feel free to play around with this in order to explore how pq
should behave.
Note, you cannot create Unix domain sockets on an AFS mount. Therefor you will need to pass in a path to the socket:
$ /afs/nd.edu/user15/pbui/pub/bin/pq -f /tmp/pq.$USER
That will run the reference implemenation with a socket located at /tmp/pq.$USER.
Traces
Here are some example traces of pq in action:
FIFO
FIFO: Server
FIFO: Client
Round Robin
Round Robin: Server
Round Robin: Client
Multi-Level Feedback Queue
Multi-Level Feedback Queue: Server
Multi-Level Feedback Queue: Client
Deliverables
As noted above, you are to work in groups of one or two (three
is permitted, but discouraged) to implement pq. You may use either C
or C++ as the implementation language. Any test scripts or auxillary
tools can be written in any reasonable scripting language.
Timeline
Here is a timeline of events related to this project:
| Date | Event |
|---|---|
| Friday, September 15 | Project description and repository are available. |
| Tuesday, September 19 | Workload scripts are available from TAs. |
| Monday, September 25 | Student organized hackathon with TAs. |
| Tuesday, September 26 | Source code is due (pushed to GitLab). |
| Tuesday, October 3 | Demonstrations must be completed. |
Repository
To start this project, one group member must fork the Project 02 repository on GitLab:
https://gitlab.com/nd-cse-30341-fa17/cse-30341-fa17-project02
Once this repository has been forked, follow the instructions from Reading 00 to:
-
Make the repository private
-
Configure access to the repository
Make sure you add all the members of the team in addition to the instructional staff.
Source Code
As you can see, the base Project 02 repository contains a README.md
file and a worksim.py. Unlike in CSE.20289.SP17, you are to write most
of the source code for this project yourself.
Pseudo-Solutions
This project relates directly to our discussion on schedulers. Refer to your textbook, Operating Systems: Three Easy Pieces and the slides on scheduling: Scheduling (FIFO, Round Robin) and Scheduling (MLFQ, Lottery).
That said, you must include a Makefile that builds and cleans up the
project (and all its components):
$ make # Builds pq $ make clean # Remove pq and any intermediate files
One script that is provided is worksim.py, which is a workload simulator.
You can use it to create a job that simulates a job with a particular I/O
workload and duration. For example, to create a job that is 30% I/O and
70% compute that runs for 10 seconds, you can run the following:
$ ./worksim.py 0.3 10
If you wish to suppress the debugging messages from worksim.py you can
set the NDEBUG environmental variable to 1 as follows:
$ NDEBUG=1 ./worksim.py 0.3 10
This script will be useful for testing and benchmarking the different scheduling policies.
If Looks Could Kill
Keep in mind that while the exact organization of the project code is up to you, but you will be graded in part on coding style, cleaniness, and organization. This means your code should be consistently formatted, not contain any dead code, have reasonable comments, and appropriate naming among other things.
Please refer to these Coding Style slides for some tips and guidelines on coding style expectations.
Demonstration
As part of your grade, you will need perform a series of benchmarks on your
implementation of pq and then present these results face-to-face
to a TA where you will demonstrate the correctness of your
implementation and to discuss the results of the project.
Benchmarks
Once you have completed your implementation of pq, you must perform a
series of benchmarks that answer the following questions:
-
What type of workloads are best for FIFO? Round Robin? Multi-Level Feedback Queue? That is, where does each shine and where does each falter?
-
How well does each scheduling policy perform when we have multiple cores and many processes (
> 100) in the queue? -
How well does each scheduling policy perform when jobs arrive in the queue at different time intervals?
To answer these questions, you will need to write some scripts, collect some data, and make some graphs. How you do this is up to you.
Workload Scripts
Workload scripts will be available from the TAs beginning next week. In order for you to receive these scripts, you must show them your responses to the Design questions. If they find them reasonable, then the TAs will provide you with the workload scripts and you can add them to your project repository.
You may use these scripts (along with your own) to help answer some of these benchmarking questions.
Presentation
To present the results of your benchmarks, you need to create a
presentation (between 5 - 10 slides) with the following content:
-
Procedure: A short description of what you benchmarked and how you benchmarked.
-
Results: Graphs and tables that show the results of your testing.
-
Analysis: Answers to the questions above in light of your results.
-
Summary: Describe what you learned.
Please upload these slides to Google Drive and place a link in your
README.md.
Be prepared to be asked about different aspects of your project, as the TA may ask you questions to probe your understanding of the material and your work.
Documentation
As noted above, the Project 02 repository includes a README.md file
with the following sections:
-
Members: This should be a list of the project members.
-
Design: This is a list of design questions that you should answer before you do any coding as they will guide you towards the resources you need.
-
Demonstration: This is where you should provide a Google Drive link to your demonstration slides.
-
Errata: This is a section where you can describe any deficiencies or known problems with your implementation.
You must complete this document report as part of your project.
Design and Implementation
You should look at the design questions in the README.md file of the
Project 02 repository. The questions there will help you design and plan
your process queue implementation.
Feel free to ask the TAs or the instructor for some guidance on these questions before attempting to implement this project.
Extra credit
Once you have completed your project, you many extend your implementation
of pq by performing either (or both) of the following modifications:
-
Protocol: In the current protocol for
pq, the server only handles one command per client request. Modify the server to handle multiple commands from a single client. This will require implementing a new protocol where the client can send a message to the server, receive a result, and then send another message without having to reconnect. -
Multiple Clients: In the current project description, the server only needs to be able to handle one client at a time. Modify the server so it can communicate with multiple clients at once.
Each of these modifications is worth 1 Point of extra credit each.
Grading
Your project will be graded on the following metrics:
| Metric | Points |
|---|---|
Source Code
|
17.0
|
Demonstration
|
5.0
|
Documentation
|
2.0
|