Project 05: MemHashed
Overview
The fifth project is to build a simplified implementation of memcached, which is an in-memory key-value store that is used for quick access to frequently used computations (ie. a cache). To support concurrent access to the cache, your library, MemHashed, must use the POSIX Threads to ensure thread-safe behavior.
To use the memcached programming paradigm, we first declare a memcached structure:
// Create Cache Structure
Cache *cache = cache_create(addrlen, page_size, policy, handler);
This object takes the size of the address space (in terms of the number
of bits), the size of each page (in terms of the number of
entries), the eviction policy (either Random or Clock, and the
handler (the function to call when a requested item is missing from the
cache). It maps an uint64_t key to a int64_t value.
Once we have this Cache structure, we can retrieve a value from the
cache with following command:
// Retrieve value associated with key
int64_t value = cache_get(cache, key);
If the value associated with the key is not in the Cache then the
provided handler will be called to generate or retrieve the missing
value, which is then stored in the cache and returned to the caller.
Likewise, we can also store values into the cache by doing the following:
// Store value associated with key
cache_put(cache, key, value);
If the Cache is full, that is it has no free space for another value,
then we must perform an eviction. To do so, we will use the specified
eviction policy to select a currently existing value for replacement
and then store the new value in the place of the evicted object.
In this way, the use of a fault handler and an eviction policy means
that Cache is similar to the paging and virtual memory systems we
have discussed in class for the last few weeks.
Hash Tree
Internally, the Cache structure in the memhashed library uses a
modified form of a hashed array tree, which combines facets of hash
tables with binary trees as shown below:
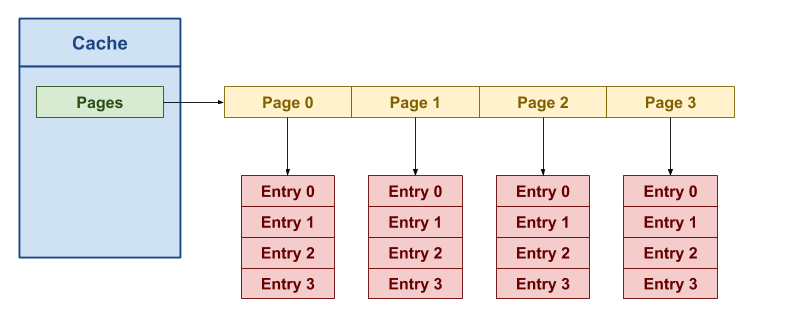
Unlike in typical hash tables, our hashed array tree splits up the
array of buckets into a tree of Pages. Rather than using the result
of the hash function to map to a specific bucket, we will simply perform
a modulus operation on the key to convert the key into a virtual
address:
VirtualAddress = key % NumberOfAddreses
Once we have this virtual address, we can then use it to navigate our hashed array tree in a manner similar to how we translate virtual address to physical addresses with page tables.
This means that inside the Cache structure, we have a pages array which
contains pointers to individual Page structures. Likewise, each Page
structure itself contains an array of Entry structures which at the very
keep track of the key and value pair associated with the Entry,
whether or not the Entry is valid, how recently the Entry was
used, and the Entry's insertion order.
To locate an item in the Cache, we must translate the key into an
address by using the modulus operator with the number of addresses in
the Cache Structure, and then use that to find the appropriate key-value
pair within our hashed array tree.
For example, the following code corresponds to the diagram above:
int64_t is_odd(const uint64_t key) {
return key % 2;
}
Cache *cache = cache_create(4, 4, RANDOM, is_odd);
printf("IsOdd(3) = %ld\n", cache_get(cache, 3));
printf("IsOdd(8) = %ld\n", cache_get(cache, 8));
The example code creates a Cache structure called cache with an
address length of 4 bits as specified by the first argument to the
Cache constructor. This means that our total address space is 2^4 =
16 addresses where each address corresponds to a Entry structure.
The second argument, 4 specifies the number of entries per Page.
Because each Page has 4 Entry structures, we need 2^4 Entries / 2^2
Entries Per Page = 2^2 = 4 Pages in our pages array.
To perform cache_get(cache, 3) (that is retrieve the value of 3 from
our Cache), we must do the following:
-
First, convert the key into an integer virtual address by using the modulus operator with the number of addresses.
In this example, this is
3 % 16 = 3. -
Next, extract the virtual page number or VPN from the integer address.
Since the virtual address is
3in this case, the bit representation is0011. Therefore the VPN is00or the first two bits of the virtual address. -
Afterwards, extract the offset into the
Pageby taking the remaining bits of the virtual address.In this case, the final bits are
11and therefore the offset is11.
In summary, we modulus the key to generate a virtual address and then extract the VPN and the offset from this virtual address:
3 % 16 -> 0 0 1 1
___ ___
VPN Offset
Once we have the VPN, we can then use this to select the appropriate
Page from the pages array. Likewise, we can then access the Entry
inside the selected Page by using the computed offset.
To perform cache_get(cache, 8) (that is retrieve the value of 8 from
our Cache), we follow the same process and get a VPN of 10 and an
offset of 00. This means we will need to lookup the first Entry of
the third Page of our pages array to find the value for the key
8.
In this way, the Cache's internal structure resembles a single-level
page table and uses a similar mechanism for translating virtual addresses
to physical address as we've discussed in class.
Working individually, you are to create a library that implements the MemHashed library described above and the collatz and coins functional tests that utilize your library by 11:59PM on Monday, November 25, 2019.
More details about this project and your deliverables are described below.
Memcached
Many websites such as Wikipedia and Wordpress utilize memcached to speed up access to their websites. In fact the notion of a fast distributed key-value store is a core component of the NoSQL movement currently sweeping the data storage and processing industry.
For our project, we will create a simplified version of memcached that
acts uses an embedded library model rather than a client/server framework.
In this way, our Cache structure is akin to sqlite, which is an
embeddable database engine that many applications such as Firefox and
Chrome utilize internally.
Deliverables
As noted above, you are to work individually to implement your memhashed library. You must use C (not C++) as the implementation language. Any test scripts or auxillary tools can be written in any reasonable scripting language.
Timeline
Here is a timeline of events related to this project:
| Date | Event |
|---|---|
| Saturday, November 09 | Project description and repository are available. |
| Saturday, November 16 | Brainstorming should be completed. |
| Monday, November 18 | Repository must be forked and set to private. |
| Monday, November 25 | Library and functional tests due (pushed to GitLab memhashed branch). |
Lock It Up!!!
If you do not fork your repository AND mark it as private by the deadline above, you will lose 3 points from your final grade.
Final Submission
For the final submission, please open a Merge Request on your
repository (for your memhashed branch to the master branch) and assign
it to your grader from the [Reading 10 TA List].
Repository
To start this project, you must fork the Project 05 repository on GitLab:
https://gitlab.com/nd-cse-30341-fa19/cse-30341-fa19-project05
Once this repository has been forked, follow the instructions from Reading 00 to:
-
Make the repository private.
-
Configure access to the repository.
Make sure you add all the members of the team in addition to the instructional staff.
Note: Do your work in a separate git branch that can be later merged
into the master branch (ie. make a memhashed branch, DO NOT COMMIT OR
MERGE TO MASTER).
Documentation
The Project 05 repository includes a README.md file with the following
sections:
-
Student: This should be your name and email address.
-
Brainstorming: This should contain your responses to the provided brainstorming questions (optional for this project).
-
Errata: This should contain a description of any known errors or deficiencies in your implementation.
-
Extra Credit: This should contain a description of any extra credit you attempted or completed.
You must complete this document report as part of your project.
Less is More
While it is tempting to write a long response to the brainstorming and reflection questions, please limit yourself to a few sentences at the most for each response.
This will facilitate more efficient grading and it will help you practice distilling ideas into their absolute essentials (which is useful for real world communication and for answering questions on exams).
Source Code
As you can see, the base Project 05 repository contains a README.md
file and the following folder hierarchy:
project05
\_ Makefile # This is the project Makefile
\_ bin # This contains the test executables and scripts
\_ include
\_ memhashed # This contains the MemHashed library header files
\_ src
\_ memhashed # This contains the MemHashed library source code
\_ tests # This contains the MemHashed test source code
You must maintain this folder structure for your project and place files in their appropriate place.
Compiling
To help you get started, we have provided a Makefile with all the
necessary targets:
$ make # Build libraries and tests
Compiling src/memhashed/queue.o
Compiling src/memhashed/cache.o
Compiling src/memhashed/page.o
Linking lib/libmemhashed.a
Compiling src/tests/unit_cache.o
Linking bin/unit_cache
Compiling src/tests/unit_page.o
Linking bin/unit_page
Compiling src/tests/func_coins.o
Linking bin/func_coins
Compiling src/tests/func_collatz.o
Linking bin/func_collatz
Compiling src/tests/func_scan.o
Linking bin/func_scan
Compiling src/tests/func_prime.o
Linking bin/func_prime
Compiling src/tests/func_fibonacci.o
Linking bin/func_fibonacci
$ make clean # Remove all targets
Removing objects
Removing libraries
Removing test programs
K.I.S.S.
While the exact organization of the project code is up to you, keep in mind that you will be graded in part on coding style, cleaniness, and organization. This means your code should be consistently formatted, not contain any dead code, have reasonable comments, and appropriate naming among other things:
-
Break long functions into smaller functions.
-
Make sure each function does one thing and does it well.
-
Abstract, but don't over do it.
Please refer to these Coding Style slides for some tips and guidelines on coding style expectations.
Running
Once you have the MemHashed library, you can use the provided tests to check your implementation:
$ make test # Run all tests
Running unit_cache 0
Running unit_cache 1
Running unit_cache 2
Running unit_page 0
Running unit_page 1
Running unit_page 2
Running unit_page 3
Testing coins with Random ... Success
Testing coins with Clock ... Success
Testing coins (mt) with RANDOM ... Success
Testing coins (mt) with CLOCK ... Success
Testing collatz with Random ... Success
Testing collatz with Clock ... Success
Testing collatz (mt) with Random ... Success
Testing collatz (mt) with Clock ... Success
Testing fibonacci with Random ... Success
Testing fibonacci with Clock ... Success
Testing fibonacci (mt) with RANDOM ... Success
Testing fibonacci (mt) with CLOCK ... Success
Testing prime with Random ... Success
Testing prime with Clock ... Success
Testing prime (mt) with RANDOM ... Success
Testing prime (mt) with CLOCK ... Success
Testing scan (10) with Random ... Success
Testing scan (10) with Clock ... Success
Testing scan (8) with Random ... Success
Testing scan (8) with Clock ... Success
Testing scan (mt) with RANDOM ... Success
Testing scan (mt) with CLOCK ... Success
Remember, you can run each unit test separately:
$ ./bin/unit_cache 0 # Run test 0 of cache unit test
In addition to unit tests, there are a few functional tests:
-
src/tests/func_scan.c: This simply reads data from an array. -
src/tests/func_prime.c: This computes prime numbers. -
src/tests/func_fibonacci.c: This recursively computes fibonacci numbers.
To utilize these functional tests, you can do the following:
# Build applications
$ make
# Scan Usage
$ ./bin/func_scan
Usage: ./bin/func_scan AddressLength PageSize EvictionPolicy Threads
# Run scan example
$ ./bin/func_scan 8 64 0 1
Hits = 184
Misses = 10056
Each functional test takes four arguments:
-
AddressLength: Number of bits in address space. -
PageSize: Number of entries per page. -
EvictionPolicy: Which eviction policy to use (Random =0, Clock =1). -
Threads: Number of threads to utilize.
To run the functional test without any caching, you can simply set
AddressLength to 0:
# Run scan example without cache
$ ./bin/func_scan 0 0 0 1
Hits = 0
Misses = 0
To check the result of your functional tests, you can run each functional test script individually:
$ ./bin/test_scan.sh
Testing scan (10) with Random ... Success
Testing scan (10) with Clock ... Success
Testing scan (8) with Random ... Success
Testing scan (8) with Clock ... Success
Note there is a multi-threaded version of each functional test to ensure you do not have any deadlocks or race conditions:
$ ./bin/test_scan_mt.sh
Testing scan (mt) with RANDOM ... Success
Testing scan (mt) with CLOCK ... Success
Implementation
All of the C header files are in the include/memhashed folder, while the
C source code for the MemHashed library is in the src folder. To
help you get started, parts of the project are already implemented:
[x] include/memhashed/cache.h # Cache structure header (implemented)
[x] include/memhashed/logging.h # Logging utilities header (implemented)
[x] include/memhashed/page.h # Page structure header (implemented)
[x] include/memhashed/queue.h # Queue structure header (implemented)
[x] include/memhashed/thread.h # Thread utilites header (implemented)
[x] include/memhashed/types.h # Tpyes header (implemented)
[ ] src/memhashed/cache.c # Cache structure definitions (not implemented)
[ ] src/memhashed/page.c # Page structure definitions (not implemented)
[x] src/memhashed/queue.c # Queue structure definitions (implemented)
Basically, all of the header files are implemented. You only need to focus
on implementing the Cache and Page structures which are at the core of
the MemHashed library. Each of the functions in the incomplete files
above have comments that describe what needs to be done.
You will need to examine these source files and complete the implementation
of the MemHashed library that utilizes a hashed array tree (as
described above) to implement an in-memory cache. To do so, you should
start with the Page structure and then move to the Cache structure.
Once you pass the provided unit tests, you should then use the functional
tests to ensure that your MemHashed library behaves properly:
-
src/memhashed/page.c: This file contains the functions for thePagestructure, which contains a number of attributes for proper management of its internalentries:-
The
page_createconstructor must determine the following attributes and then initialize theentriesarray based on these values.nentries: This is the number of entries per page (specified by user).policy: This is the policy to use when an entry must be evicted (specified by user).entries: This is the array ofEntrystructures.
-
The
page_getfunction must use [linear probing] to locate the appropriateEntry. If it is not found, then it must return anEntrywith akeythat is different from the user specifiedkey. -
The
page_putfunction must also use [linear probing] to locate the appropriateEntry. If noEntryis found, then it should overwrite an invalidEntry. If thePageis full, an existingEntrymust be selected based on the evictionpolicyand then used for replacement.You will have to implement each of these eviction policies individually in separate helper functions that you can call in your
page_putfunction.
Since multiple threads can access each
Pageconcurrently, you must use thelockattribute to implement monitor-style protection.Note: For clock, you will need to keep track of the
usedattribute of eachEntryin thePage. To set theusedattribute, you should first incremente thePage'susedcounter (aka logical clock) and then assign the new value to theEntry'susedattribute as follows:// Set used attribute of Entry in Page with logical clock page->entries[offset].used = ++page->used -
-
src/memhashed/cache.c: This file contains the functions for theCachestructure, which contains a number of attributes necessary for proper management of its internalpages:-
The
cache_createconstructor must determine the following attributes and then initialize thepagesarray based on these values.addrlen: This is the number of bits in the virtual address (specified by user).page_size: This is the number of entries per page (specified by user).policy: This is the policy to use when an entry must be evicted (specified by user).-
handler: This is the handler function to user when an entry is not found (specified by user). -
naddresses: This is the maximum number of virtual addresses (based onaddrlen). npages: This is the maximum number pages in the cache (based onnaddressesandpage_size).vpn_shift: This is the number of bits required to shift the VPN (based onaddrlen).vpn_mask: This is the mask required to extract the VPN from a virtual address (based onnpagesandvpn_shift).-
offset_mask: This is the mask required to extract the offset from a virtual address (based onvpn_shift). -
pages: This is the array ofPagepointers. lock: This is the mutex used to synchronize access to the internals of the cache.
-
The
cache_getfunction must determine the virtual address, VPN, and offset based on thekey, and then use this information to retrieve the value from the appropriatePage.It must take care of the case where the data is missing (ie. the returned
Entryhas a mismatchingkey). In this situation, it must call thehandlerfunction to compute the appropriate value and then store that into the cache before returning this new value. -
The
cache_putmethod must also determine the virtual address, VPN, and offset based on thekey, and then use this information to store the value into the appropriatePage.
To keep track of the cache hits and misses, you must update the
hitsandmissesattributes appropriately. All of the information that you determine and track will be dumped to a stream by the providedcache_statsfunction.Because multiple threads can access the
Cacheconcurrently, you are to use the providedlockattribute judiciously to protect values that need to be updated atomically. -
Note: There are also some TODOs to help identify which parts you need
to implement, along with how you will want to modify the counters.
Functional Test: Collatz
In addition to building the MemHashed library, you are also given a
src/tests/func_collatz.c skeleton. You are to complete this program by
using your MemHashed library to memoize the computation of Collatz
sequence lengths:
The Collatz conjecture is a conjecture in mathematics that concerns a sequence defined as follows: start with any positive integer n. Then each term is obtained from the previous term as follows: if the previous term is even, the next term is one half the previous term. If the previous term is odd, the next term is 3 times the previous term plus 1. The conjecture is that no matter what value of n, the sequence will always reach 1.
For example, given the input 22, the following sequence of numbers would
be generated by the Collatz conjecture:
22 11 34 17 52 26 13 40 20 10 5 16 8 4 2 1
This sequence contains 16 numbers, so we would say that the Collatz
sequence length for 22 is 16.
Given any integer n, we could compute the length of the Collatz
sequence using the following recursive algorithm:
def collatz_length(n):
if n == 1:
return 1
if is_odd(n):
return collatz_length(3*n + 1) + 1
else:
return collatz_length(n / 2) + 1
You are to complete src/tests/func_collatz.c such that it reads in a
stream of integers from standard input and computes the Collatz sequence
length of each integer. To speed up computation, we will use our
MemHashed library to memoize overlapping computations.
Additionally, we will support utilizing multiple threads to handle
different input integers concurrently. To coordinate the worker threads,
you are to use the provided Queue structure, which internally uses
semaphores for synchronization (we implemented in class in Lecture 12).
You will need to think carefully about how and when to use the Cache and
Queue to implement this application.
Functional Test: Coins
In addition to src/tests/func_collatz.c, you are also given a
src/tests/func_coins.c skeleton. You are to complete this program by
using your MemHashed library to implement a dynamic programming
solution to the classic coins problem:
What is the minimum number of US coins (
25,10,5,1) necessary to make a certain amount of change:
For instance, to make change for 17 cents, we can use 10 + 5 + 1 +
1 for a minimum number of 4 coins.
To perform a dynamic programming solution, we can build a table using the following recurrence relationship:
Coins(Amount) = Minimum(
Coins(Amount - BaseCoin) for BaseCoin in BaseCoins
)
You are to complete src/tests/func_coins.c such that it computes the
number of coins necessary to produce change between between 0 and 99
cents using the US coins (25, 10, 5, 1).
You will need to think carefully about how and when to use the Cache and
to implement this application.
Extra credit
Once you have completed your project, you may do one of the following for 2.0 points of extra credit:
Implement a multi-threaded MemHashed server that responds to HTTP requests (
GETandPUT) and provide a basic demonstration of it in action.There is a race condition in the current design of the
Cache. Identify the bug and then redesign theCacheandPagestructures.
Grading
Your project will be graded on the following metrics:
| Metric | Points |
|---|---|
Source Code
|
23.0
|
Documentation
|
1.0
|
Commit History
To encourage you to work on the project regularly (rather than leaving it until the last second) and to practice performing incremental development, part of your grade will be based on whether or not you have regular and reasonably sized commits in your git log.
That is, you will lose a point if you commit everything at once near the project deadline.
Error Handling
In addition to meeting the functional requirements of the project (as described above), your program must not exhibit any memory leaks or invalid memory accesses as would be detected by Valgrind.
Additionally, because [system calls] can fail, your program must implement robust error handling and ensure your code checks the status of [system calls] when reasonable.
Moreover, you code must compile without any warnings (and -Wall must
be one of the CFLAGS).