Notebook 08: Data Manipulation
Overview
The goal of this assignment is to allow you to practice manipulating data in CSV and JSON format using the Python programming language. Additionally, you will have an opportunity for open-ended exploration.
To record your solutions and answers, create a new Jupyter Notebook
titled Notebook08.ipynb and use this notebook to complete the following
activities and answer the corresponding questions.
Make sure you label your activities appropriately. That is for Activity 1, have a header cell that is titled Activity 1. Likewise, use the Markdown cells to answer the questions (include the questions above the answer).
This Notebook assignment is due Midnight Friday, November 13, 2015 and is to be done individually or in pairs.
Partners
Both members of each pair should submit a Notebook. Be sure to identify your partner at the top of the Notebook.Activity 0: Utilities
To help you complete this Notebook, here are the solutions to Activity 0 of Notebook07:
# Imports
import os
import requests
import zipfile
import StringIO
# Functions
def ls(path=os.curdir, sort=True):
''' Lists the contents of directory specified by path '''
filelist = os.listdir(path)
if sort:
filelist.sort()
for filename in filelist:
print filename
def head(path, n=10):
''' Lists the first n lines of file specified by path '''
for count, line in enumerate(open(path, 'r')):
if count >= n:
break
line = line.strip()
print line
def tail(path, n=10):
''' Lists the last n lines of file specified by path '''
for line in open(path, 'r').readlines()[-n:]:
line = line.strip()
print line
def download_and_extract_zipfile(url, destdir):
''' Downloads zip file from url and extracts the contents to destdir '''
response = requests.get(url)
zipdata = zipfile.ZipFile(StringIO.StringIO(response.content))
zipdata.extractall(destdir)
Feel free to use these functions to help you retrieve and explore the datasets in the following activities.
Activity 1: Movie Lens
The first activity is to explore data from the MovieLens project:
MovieLens is a research site run by GroupLens Research at the University of Minnesota. MovieLens uses "collaborative filtering" technology to make recommendations of movies that you might enjoy, and to help you avoid the ones that you won't. Based on your movie ratings, MovieLens generates personalized predictions for movies you haven't seen yet. MovieLens is a unique research vehicle for dozens of undergraduates and gradute students researching various aspects of personalization and filtering technologies.
This is basically a collection of movie ratings that contains information such as movie titles, ratings, genres, years, etc. similar to what you would find on Netflix.
Your goal for this activity is to explore the data in the MovieLens by asking two questions and then writing code to help you answer them.
For instance, you may wish to explore the following questions:
-
Which movie has the least/most genres?
-
Which movie has the lowest/highest rating?
-
Which animated movie has the lowest/highest rating?
-
Which sci-fi movie from the 1990's is rated the highest?
-
How many fantasy movies from the year 1998 were rated?
-
What movies do programmers enjoy the most?
The possibilities are endless!
Examples
Here is an example of how to retrieve the Movie Lens using
the download_and_extract_zipfile function from Notebook07:
# Constants
MOVIE_LENS_URL = 'http://files.grouplens.org/datasets/movielens/ml-1m.zip'
MOVIE_LENS_DIR = 'movielens'
# Download Movie Lens 1-M dataset
download_and_extract_zipfile(MOVIE_LENS_URL, MOVIE_LENS_DIR)
Here is an example of how to answer the question: "How many movie genres are in the Movie Lens dataset?"
# Movie record constants
MOVIE_ID = 0
MOVIE_TITLE = 1
MOVIE_GENRES = 2
# Count Genres Functions
def count_genres(path):
''' Returns a dictionary containing the number of movies per genre in file specified by path '''
genres = {}
for line in open(path):
movie = line.strip().split('::')
for genre in movie[MOVIE_GENRES].split('|'):
genres[genre] = genres.get(genre, 0) + 1
return genres
# Perform count on MovieLens 1M dataset
count_genres(os.path.join(MOVIE_LENS_DIR, 'ml-1m', 'movies.dat'))
{'Action': 503,
'Adventure': 283,
'Animation': 105,
"Children's": 251,
'Comedy': 1200,
'Crime': 211,
'Documentary': 127,
'Drama': 1603,
'Fantasy': 68,
'Film-Noir': 44,
'Horror': 343,
'Musical': 114,
'Mystery': 106,
'Romance': 471,
'Sci-Fi': 276,
'Thriller': 492,
'War': 143,
'Western': 68}
Hints
The following are hints and suggestions that will help you complete this activity:
-
Download the dataset and explore the files in the
ml-1mdirectory. In particular, take a look at the README.txt file which describes the dataset. -
Use the Notebook to explore the files by writing small functions or code snippets to manipulate the data.
-
Some questions will require to look at data from multiple files (ie.
movies.datandratings.dat). You will need to think about what you want to store and keep track of and how you wish to accomplish that. You may end up with multiple datasets that link to each other! -
Unfortunately, because the 1M Dataset uses
::as a delimiter, you will not be able to use the csv module to parse the files. Instead, use str.split.
Questions
After completing the activity above, answer the following questions:
-
Describe the two questions you asked and discuss the answers you found.
-
For each question, explain how you used code to manipulate the data in order to explore the dataset and answer your questions.
-
What challenges did you face and how did you overcome these obstables? What sort of questions were difficult to ask?
Notebook Clean-up
Please clean-up the final Notebook you submit so it only holds the relevant code and explanations (rather than all your experiments).Activity 2: Currency Converter
The second activity is to create a currency conversion application using real-time currency data from the Yahoo Finance, which looks something like this:
{
"list" : {
"meta" : {
"type" : "resource-list",
"start" : 0,
"count" : 173
},
"resources" : [
{
"resource" : {
"classname" : "Quote",
"fields" : {
"name" : "USD/KRW",
"price" : "1136.045044",
"symbol" : "KRW=X",
"ts" : "1446671220",
"type" : "currency",
"utctime" : "2015-11-04T21:07:00+0000",
"volume" : "0"
}
}
}
,
... SNIP ...
Your goal for this activity is to explore the Currency JSON Feed and then design an interactive currency converter that looks like this:
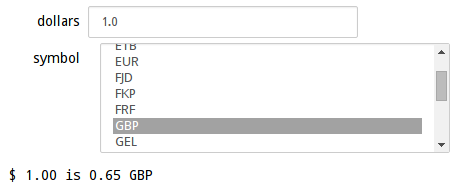
Mr. Anderson
This activity was suggested to me by my friend David Anderson (aka "Blue Eyes"). Apparently, whenever he learns a new programming language, this is one of the applications he writes to explore the new language.Functions
To complete this activity, we can break the activity down into the following functions:
def extract_currencies(url):
''' Return a list of currency objects from the JSON feed specified by URL '''
Given a
url, this performs a requests.get on theurland then processes the JSON feed to extract the currency objects in the feed and returns the currencies in a list.
def build_conversion_table(currencies):
''' Return a data structure that maps currency symbols to currency prices '''
Given a list of
currencies, this build a data structure that allows users to lookup conversion prices based on currency symbols.
def currency_converter(dollars, symbol):
''' Prints the amount in dollars to the amount specified by the foreign currency symbol '''
Given an amount in
dollars, this converts the dollars into the foreign currency specified bysymboland prints the result.
Hints
The following are hints and suggestions that will help you complete this activity:
-
Remember that you can convert the JSON response you get from requests.get into a Python object by doing something like this:
data = requests.get(url).json()Once you have converted the JSON response into a Python object, you can manipulate the data using normal Python commands.
-
JSON uses the same syntax as Python to distinguish between lists and dictionaries (ie. '[]', '{}').
-
The Yahoo Finance's Currency JSON Feed is a deeply nested data structure that will require some exploration to understand.
-
Remember that if you want a string to be treated as a
floatthen you must explicitly cast it. -
Because there are many currencies, you will want to use a
Selectwidget rather thanDropDownbox for interact. To do this, you can use the following code:from IPython.display import HTML, display from IPython.html.widgets import Select from IPython.html.widgets.interaction import interact interact(currency_converter, dollars='', symbol=Select(options=symbols))
Questions
After completing the activity above, answer the following questions:
-
Describe the contents of the Yahoo Finance's Currency JSON Feed. How did you extract each individual currency from the JSON feed? What does each currency object contain?
-
Describe how you built the conversion table. What data structure did you use?
-
Discuss how your currency converter uses the conversion table to translate dollars into foreign currency. What was the most difficult part of this activity? How did you overcome it?
Submission
To submit your notebook, follow the same directions for Notebook00, except store this notebook in the notebook08 folder.