TraceLab Components for Generating Speech Act Types in Developer
Question/Answer Conversations
Rrezarta Krasniqi, Collin
McMillan
How to Reproduce the Experiment
This page contains the Madeline experiment with the ND
components. To reproduce Madeline experiment in TraceLab, below
are the steps to run the experiment:
- Open VirtualBox and import the VirtualMachine(Debian)
"madeline_tracelab.ova" found here.
The successful import is shown in VM. Then run tracelab.

- Open the terminal (highlighted in red) and type: tracelab.

- If an error occurs with a message "canberra-gtk-module" (as
highlighted in red), ignore it (i.e., the module is alreday installed)
and re-run it again. The new tracelab screen opens (highlighted in
orange)

- The madeline_complete_exp.teml is the executable file that
runs the madeline experiment. To locate this file, follow the steps
below:
- Open everyman folder -- label (2)
- Follow the directory path -- label (3).
- Open madeline_complete_exp.teml file -- label (4).

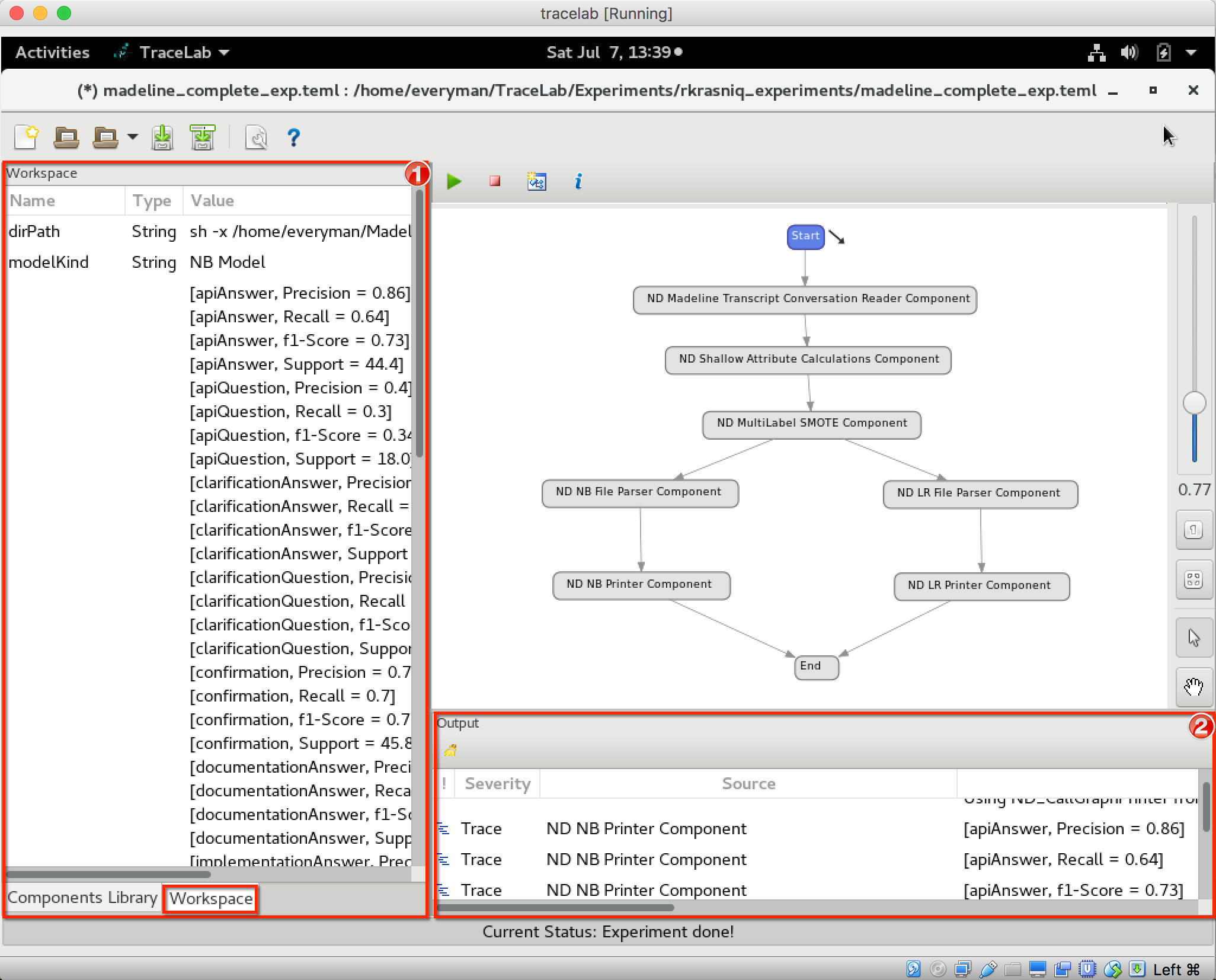
- This snapshot shows the ND Madeline sample experiment for TraceLab.
All components available in this experiment were developed by the ND
TraceLab.

- To run the experiment: select the start node (1), then
click the green run button at the top left corner (2).

- The results are reported within the Tracelab both in workspace --
label (1) and log space -- label (2). Note that the output shows the
generated speech acts (e.g., apiAnswer, clarificationQuestion,
confirmation, etc) of different types and their corresponding
performance metrics (ie., precision, recall, f-1-score
and support).
- The same output results also can be found in the directory: /home/everyman/Madeline/extension/results/experiment_1.
To locate the output files, follow steps labeled (1) -- (5):
- Open icon label (1)
- Open everyman folder -- label (2)
- Follow the directory path -- label (3).
- Change default ''Experiment files (.teml)" to "All files" -- label
(4)
- Open output files:
- nb_5_fold_cv_results.txt -- label (5)
- lr_5_fold_cv_results.txt -- label (5)

Details about Data
The data that are being used to generate the speech acts are:
- Skype transcripts (found at: /home/everyman/Madeline/data/SkypeTranscripts).
Skype transcripts are dialogues collected by virtual assistant and
programmer. Programmer's role was to ask "virutal assistant" questions
during the bug repair. Questions were of different type such as:
implementation questions or clarification questions, .etc. The
"virtual assistant's" role was to assist with hints to guide the
programmer to repair the bug.
- codes.csv -- is the file that contains the
listing of all participants along with annotation labels (e.g,
clarificationQuestion, implementationQuestion, etc).
- participant1.txt. . .participant30.txt - are the
files that provide conversations collected between participant
and virtual assistant.
- results.csv -- is the file that contains each
line of text (i.e. speech act) that needs to be classified and its
corresponding annotation label
that is expected
-
Generated data are:
- Performance metrics calculated for each speech act type (found at:
/home/everyman/Madeline/extension/results/).
- nb_5_fold_cv_results.txt
- lr_5_fold_cv_results.txt
-
Prediction
where each speech act type is the text to be classified and the annotated
label is computed indirectly through a python call via "ND
Shallow Attribute Calculations Component".
- shallow_attribute_calculations.py (found at: /home/everyman/Madeline/extension)
- shallow_attribute_calculations.py - invokes:
- experiment_handles.create_cv_experiment_function(experiment_classifiers)
from:
- function_handles.py (found at:
/home/everyman/Madeline/experiment_handles/) .
Finally the resulting list of classifiers are then tested
through 5 fold cross-validation.
Further details about data interpretation are provided in the FSE'18
paper. Please, see section 9 (page 9 and 10), respectively,
subsections: 9.1, 9.2 and 9.3.
Component Configurations
Here we show in detail the configurations
(ie., input/output) of each component.
- The first component "ND Madeline Transcript Conversation Reader
Component" is selected in this picture. It requires as output the path
to the folder of transcript reader script. For more details on the "ND
Madeline Transcript Conversation Reader Component" click here.

- The "ND Shallow Attribute Calculations Component" is selected in this
picture. It requires as output the path to the folder of shallow
attribute scripts. For more details on the "ND Shallow Attribute
Calculations Component" click here.

- The "ND MultiLabel SMOTE Component" is selected in this picture.
It requires the user to enter which prediction model to run. In this
case, if we choose to compute NB (i.e., Naive Bayes) model, then from
"ND MultiLabel SMOTE Component" entry we type "NB Model".
Otherwise, if we choose to compute LR (i.e., Logistic Regression) model,
then from "ND MultiLabel SMOTE Component" entry, we type "LR Model".
For more details on the "ND MultiLabel SMOTE Component" click here.

- The "ND NB File Parser Component" is selected in this picture. It
loads from the workspace the entry that was processed by the ND
MultiLabel SMOTE Component. It requires the user to inform the path to
directory in order to store NB results. For more details on the "ND NB
File Parser Component" click here.

- The "ND NB Printer Component" is selected in this picture. It will
received from the workspace the contents of the srcml file that was
processed by the ND NB File Parser Component. The ND NB Printer
Component will print the contents of the of the workspace to TraceLab's
log space. For more details on the "ND Printer Component" click here.

- The "ND LR File Parser Component" is selected in this picture. It will
receive from the workspace the entry that was processed by the ND
MultiLabel SMOTE Component. It requires the user to inform the path to
directory in order to print the LR results. The path where the results
are stored are shown in the workspace of Tracelab. For more details on
the "ND LR File Parser Component" click here.

- The "ND LR Printer Component" is selected in this picture. It will
received from the workspace the contents of the srcml file that was
processed by the ND LR File Parser Component. The ND LR Printer
Component will print the contents of the of the workspace to TraceLab's
log space. For more details on the "ND LR Printer Component" click here.

Table of Contents
Downloads